
리플 프로토콜 합의 알고리즘
Abstract
हालांकि Byzantine Generals Problem के लिए कई सहमति एल्गोरिदम मौजूद हैं, विशेष रूप से वितरित भुगतान प्रणालियों के संबंध में, उनमें से कई नेटवर्क के सभी नोड्स को समकालिक रूप से संवाद करने की आवश्यकता के कारण उच्च विलंबता से ग्रस्त हैं। इस कार्य में, हम एक नवीन सहमति एल्गोरिदम प्रस्तुत करते हैं जो बड़े नेटवर्क के भीतर सामूहिक रूप से विश्वसनीय उप-नेटवर्क का उपयोग करके इस आवश्यकता को दरकिनार करता है। हम दिखाते हैं कि Sybil हमलों को रोकने के लिए आवश्यक "विश्वास" वास्तव में वैश्विक नहीं है, बल्कि नेटवर्क में प्रत्येक नोड के लिए स्थानीय है।
Ripple प्रोटोकॉल सहमति एल्गोरिदम (RPCA) नेटवर्क की शुद्धता और सहमति बनाए रखने के लिए सभी नोड्स द्वारा हर कुछ सेकंड में लागू किया जाता है। एक बार सहमति प्राप्त हो जाने पर, वर्तमान लेजर को "बंद" माना जाता है और यह अंतिम-बंद लेजर बन जाता है। यह एल्गोरिदम अद्वितीय है क्योंकि यह Byzantine विफलताओं के खिलाफ मजबूत गारंटी बनाए रखते हुए कम विलंबता के साथ सहमति प्राप्त करता है, जो इसे वास्तविक समय वित्तीय निपटान प्रणालियों के लिए उपयुक्त बनाता है।
Abstract
Byzantine Generals Problem에 대한 여러 합의 알고리즘이 존재하지만, 특히 분산 결제 시스템과 관련하여 많은 알고리즘이 네트워크 내 모든 노드가 동기적으로 통신해야 하는 요구사항으로 인해 높은 지연 시간 문제를 겪고 있다. 본 연구에서는 더 큰 네트워크 내에서 집합적으로 신뢰할 수 있는 하위 네트워크를 활용하여 이 요구사항을 우회하는 새로운 합의 알고리즘을 제시한다. Sybil 공격을 방지하기 위해 필요한 "신뢰"가 실제로는 전역적인 것이 아니라 네트워크 내 각 노드에 대해 지역적임을 보여준다.
Ripple 프로토콜 합의 알고리즘(RPCA)은 네트워크의 정확성과 합의를 유지하기 위해 모든 노드에 의해 수 초마다 적용된다. 합의에 도달하면 현재 원장은 "폐쇄"된 것으로 간주되며 마지막으로 폐쇄된 원장(last-closed ledger)이 된다. 이 알고리즘은 Byzantine 장애에 대한 강력한 보장을 유지하면서 낮은 지연 시간으로 합의를 달성한다는 점에서 독특하며, 실시간 금융 결제 시스템에 적합하다.
Introduction
एक वितरित भुगतान प्रणाली को दोषपूर्ण या दुर्भावनापूर्ण अभिकर्ताओं की उपस्थिति में भी भुगतानों को सही और समय पर संसाधित करने के लिए एक सहमति एल्गोरिदम लागू करना होगा। Bitcoin प्रूफ-ऑफ-वर्क (proof-of-work) का उपयोग करके सहमति प्राप्त करता है, जिसमें सभी नोड्स को क्रिप्टोग्राफिक पहेलियों को हल करने के लिए कम्प्यूटेशनल संसाधन खर्च करने की आवश्यकता होती है। हालांकि यह दृष्टिकोण मजबूत सुरक्षा गारंटी प्रदान करता है, इसमें महत्वपूर्ण कमियां हैं जिनमें उच्च ऊर्जा खपत, कम लेनदेन थ्रूपुट और लंबी पुष्टि विलंबता शामिल है जो उच्च-मूल्य लेनदेन के लिए एक घंटे या उससे अधिक तक बढ़ सकती है।
Ripple प्रोटोकॉल सहमति एल्गोरिदम वितरित सहमति के लिए एक नया दृष्टिकोण प्रदान करता है जिसमें प्रूफ-ऑफ-वर्क की आवश्यकता नहीं होती। इसके बजाय, नेटवर्क में नोड्स एक मतदान प्रक्रिया के माध्यम से लेनदेन सेट पर सामूहिक रूप से सहमत होते हैं जो सेकंडों में सहमति प्राप्त करती है। यह सहमति तंत्र विशेष रूप से एक वैश्विक भुगतान नेटवर्क की आवश्यकताओं के लिए डिज़ाइन किया गया है, जहां व्यावहारिक तैनाती के लिए कम विलंबता और उच्च थ्रूपुट आवश्यक हैं।
RPCA में प्रमुख नवाचार यह है कि इसमें नेटवर्क के सभी नोड्स को एक-दूसरे से सहमत होने की आवश्यकता नहीं होती। इसके बजाय, प्रत्येक नोड अन्य नोड्स की एक Unique Node List (UNL) बनाए रखता है जिन पर वह मिलीभगत न करने का भरोसा करता है। जब तक नोड्स द्वारा चुनी गई UNL में पर्याप्त ओवरलैप होता है, और नोड्स का एक सीमा प्रतिशत से कम दोषपूर्ण होता है, तब तक नेटवर्क सहमति प्राप्त करेगा। यह दृष्टिकोण भुगतान प्रणाली के लिए आवश्यक सुरक्षा गारंटी प्रदान करता है जबकि सहमति विलंबता को मिनटों या घंटों के बजाय सेकंडों में मापा जाता है।
Introduction
분산 결제 시스템은 결함이 있거나 악의적인 행위자가 존재하는 상황에서도 적시에 올바르게 결제를 처리하기 위해 합의 알고리즘을 구현해야 한다. 비트코인은 작업 증명(proof-of-work)을 사용하여 합의를 달성하며, 이는 모든 노드가 암호화 퍼즐을 풀기 위해 계산 자원을 소비하도록 요구한다. 이 접근 방식은 강력한 보안 보장을 제공하지만 높은 에너지 소비, 낮은 트랜잭션 처리량, 그리고 고가치 트랜잭션의 경우 1시간 이상까지 늘어날 수 있는 긴 확인 지연 시간을 포함한 상당한 단점이 있다.
Ripple 프로토콜 합의 알고리즘은 작업 증명을 필요로 하지 않는 분산 합의에 대한 새로운 접근 방식을 제공한다. 대신, 네트워크의 노드들은 수 초 내에 합의를 달성하는 투표 과정을 통해 트랜잭션 집합에 대해 집단적으로 동의한다. 이 합의 메커니즘은 실질적인 배포를 위해 낮은 지연 시간과 높은 처리량이 필수적인 글로벌 결제 네트워크의 요구사항에 맞춰 특별히 설계되었다.
RPCA의 핵심 혁신은 네트워크의 모든 노드가 서로 동의할 필요가 없다는 점이다. 대신, 각 노드는 공모하지 않을 것으로 신뢰하는 다른 노드들의 고유 노드 목록(Unique Node List, UNL)을 유지한다. 노드들이 선택한 UNL이 충분한 중첩을 가지고 있고, 임계값 비율 미만의 노드만 결함이 있다면 네트워크는 합의에 도달할 것이다. 이 접근 방식은 합의 지연 시간을 분이나 시간이 아닌 초 단위로 측정하면서 결제 시스템에 필요한 보안 보장을 제공한다.
Definition of Consensus
वितरित प्रणालियों में, सहमति उस प्रक्रिया को संदर्भित करती है जिसके द्वारा नोड्स का एक नेटवर्क दोषपूर्ण या दुर्भावनापूर्ण प्रतिभागियों की उपस्थिति के बावजूद एक साझा स्थिति पर सहमति पर पहुंचता है। एक सहमति एल्गोरिदम को तीन मूलभूत गुणों को संतुष्ट करना चाहिए: शुद्धता (कोई भी दो सही नोड अलग-अलग निर्णय नहीं लेते), सहमति (सभी सही नोड एक ही निर्णय पर पहुंचते हैं), और समाप्ति (सभी सही नोड अंततः निर्णय लेते हैं)। ये गुण सुनिश्चित करते हैं कि वितरित प्रणाली ऐसे व्यवहार करती है जैसे कि वह एक एकल, विश्वसनीय नोड हो।
सहमति प्राप्त करने की चुनौती वितरित प्रणालियों की अंतर्निहित अविश्वसनीयता से उत्पन्न होती है। नोड्स क्रैश हो सकते हैं, संदेश विलंबित या खो सकते हैं, और Byzantine नोड्स मनमाने ढंग से या दुर्भावनापूर्ण तरीके से व्यवहार कर सकते हैं। Byzantine Generals Problem, जिसे Lamport, Shostak और Pease ने औपचारिक रूप दिया, इस चुनौती को पकड़ती है: प्रक्रियाओं का एक समूह कैसे सहमति पर पहुंच सकता है जब कुछ अंश दोषपूर्ण हो सकता है और जब संचार अविश्वसनीय हो?
वितरित कंप्यूटिंग में शास्त्रीय परिणाम इस बात की मूलभूत सीमाएं स्थापित करते हैं कि सहमति एल्गोरिदम क्या हासिल कर सकते हैं। FLP असंभवता परिणाम दिखाता है कि कोई भी नियतात्मक एल्गोरिदम एक असमकालिक प्रणाली में सहमति की गारंटी नहीं दे सकता यदि एक भी नोड विफल हो सकता है। इसलिए व्यावहारिक सहमति एल्गोरिदम को सुरक्षा (कभी भी गलत सहमति नहीं पहुंचना) और जीवंतता (हमेशा प्रगति करना) के बीच समझौता करना होगा। Bitcoin का proof-of-work जीवंतता पर सुरक्षा को प्राथमिकता देता है, जबकि RPCA यथार्थवादी दोष धारणाओं के तहत मजबूत सुरक्षा गारंटी बनाए रखते हुए सीमित समय में सहमति दौर पूरा करके भुगतान प्रणालियों के लिए अधिक उपयुक्त संतुलन प्राप्त करता है।
Definition of Consensus
분산 시스템에서 합의란 결함이 있거나 악의적인 참가자가 존재하는 상황에서도 노드 네트워크가 공유 상태에 대한 동의에 도달하는 과정을 말한다. 합의 알고리즘은 세 가지 기본 속성을 만족해야 한다: 정확성(두 개의 올바른 노드가 서로 다르게 결정하지 않음), 동의(모든 올바른 노드가 동일한 결정에 도달함), 그리고 종료(모든 올바른 노드가 결국 결정을 내림). 이러한 속성은 분산 시스템이 단일의 신뢰할 수 있는 노드처럼 동작하도록 보장한다.
합의를 달성하는 데 있어서의 도전은 분산 시스템의 본질적인 불안정성에서 비롯된다. 노드가 충돌할 수 있고, 메시지가 지연되거나 손실될 수 있으며, Byzantine 노드는 임의적으로 또는 악의적으로 행동할 수 있다. Lamport, Shostak, Pease가 공식화한 Byzantine Generals Problem은 이 도전을 포착한다: 일부가 결함이 있을 수 있고 통신이 불안정한 상황에서 프로세스 그룹이 어떻게 합의에 도달할 수 있는가?
분산 컴퓨팅의 고전적 결과들은 합의 알고리즘이 달성할 수 있는 것의 근본적 한계를 확립한다. FLP 불가능성 결과는 단 하나의 노드만 실패할 수 있는 비동기 시스템에서도 어떤 결정론적 알고리즘도 합의를 보장할 수 없음을 보여준다. 따라서 실용적인 합의 알고리즘은 안전성(잘못된 합의에 절대 도달하지 않음)과 활성(항상 진행함) 사이에서 절충해야 한다. 비트코인의 작업 증명은 활성보다 안전성을 우선시하는 반면, RPCA는 현실적인 결함 가정 하에서 강력한 안전성 보장을 유지하면서 제한된 시간 내에 합의 라운드를 완료함으로써 결제 시스템에 더 적합한 균형을 달성한다.
Existing Consensus Algorithms
वितरित प्रणालियों में Byzantine Generals Problem को हल करने के लिए कई सहमति एल्गोरिदम प्रस्तावित किए गए हैं। Practical Byzantine Fault Tolerance (PBFT) एल्गोरिदम, जिसे Castro और Liskov ने पेश किया, 3f+1 नोड्स की प्रणाली में f Byzantine दोषों तक सहन कर सकता है। PBFT सभी नोड्स के बीच संदेश विनिमय के कई दौरों के माध्यम से सहमति प्राप्त करता है, जिसमें O(n^2) की संचार जटिलता होती है, जहां n नोड्स की संख्या है। हालांकि PBFT छोटे नेटवर्क के लिए मजबूत सुरक्षा गारंटी और अपेक्षाकृत कम विलंबता प्रदान करता है, द्विघात संचार ओवरहेड के कारण यह बड़े नेटवर्क के लिए अच्छी तरह से स्केल नहीं करता।
Paxos और इसके संस्करण, Lamport द्वारा विकसित, असमकालिक प्रणालियों में सहमति प्रदान करते हैं लेकिन Byzantine दोषों के बजाय क्रैश विफलताओं को मानते हैं। Paxos दौरों की एक श्रृंखला के माध्यम से सहमति प्राप्त करता है जिसमें प्रस्तावक मूल्य सुझाते हैं और स्वीकर्ता उन पर मतदान करते हैं। हालांकि Paxos मनमानी संदेश विलंबता और प्रक्रिया क्रैश को सहन कर सकता है, इसमें Byzantine विफलताओं को संभालने के लिए सावधानीपूर्वक इंजीनियरिंग की आवश्यकता होती है और कुछ परिदृश्यों में livelock से ग्रस्त हो सकता है।
Bitcoin का proof-of-work सहमति एल्गोरिदम Byzantine हमलों को आर्थिक रूप से अव्यवहार्य बनाकर एक मौलिक रूप से भिन्न दृष्टिकोण अपनाता है। नोड्स क्रिप्टोग्राफिक पहेलियों को हल करने के लिए प्रतिस्पर्धा करते हैं, विजेता लेनदेन का अगला ब्लॉक प्रस्तावित करता है। हालांकि यह दृष्टिकोण मनमाने नेटवर्क आकार तक स्केल करता है और Byzantine दोषों को संभालता है, इसमें गंभीर कमियां हैं: भारी ऊर्जा खपत (Bitcoin नेटवर्क के लिए प्रति वर्ष 150 मिलियन डॉलर से अधिक अनुमानित), लंबी पुष्टि विलंबता (उच्च-मूल्य लेनदेन के लिए अक्सर 40-60 मिनट), और सीमित थ्रूपुट (लगभग 7 लेनदेन प्रति सेकंड)। ये सीमाएं proof-of-work को कई भुगतान प्रणाली अनुप्रयोगों के लिए अनुपयुक्त बनाती हैं जिनमें तेजी से निपटान और उच्च लेनदेन मात्रा की आवश्यकता होती है।
Existing Consensus Algorithms
분산 시스템에서 Byzantine Generals Problem을 해결하기 위해 여러 합의 알고리즘이 제안되었다. Castro와 Liskov가 도입한 Practical Byzantine Fault Tolerance(PBFT) 알고리즘은 3f+1개의 노드로 구성된 시스템에서 최대 f개의 Byzantine 결함을 허용할 수 있다. PBFT는 모든 노드 간의 여러 라운드의 메시지 교환을 통해 합의를 달성하며, 통신 복잡도는 O(n^2)으로, 여기서 n은 노드의 수이다. PBFT는 강력한 안전성 보장과 소규모 네트워크에서 상대적으로 낮은 지연 시간을 제공하지만, 이차적 통신 오버헤드로 인해 대규모 네트워크로 잘 확장되지 않는다.
Lamport가 개발한 Paxos와 그 변형들은 비동기 시스템에서 합의를 제공하지만 Byzantine 결함이 아닌 충돌 결함을 가정한다. Paxos는 제안자가 값을 제안하고 수락자가 투표하는 일련의 라운드를 통해 합의를 달성한다. Paxos는 임의의 메시지 지연과 프로세스 충돌을 허용할 수 있지만, Byzantine 결함을 처리하기 위해서는 세심한 엔지니어링이 필요하며 특정 시나리오에서 라이브락(livelock)이 발생할 수 있다.
비트코인의 작업 증명 합의 알고리즘은 Byzantine 공격을 경제적으로 불가능하게 만드는 근본적으로 다른 접근 방식을 취한다. 노드들은 암호화 퍼즐을 풀기 위해 경쟁하며, 승자가 다음 트랜잭션 블록을 제안한다. 이 접근 방식은 임의의 네트워크 크기로 확장되고 Byzantine 결함을 처리하지만, 심각한 단점이 있다: 엄청난 에너지 소비(비트코인 네트워크에 대해 연간 1억 5천만 달러 이상으로 추정), 긴 확인 지연 시간(고가치 트랜잭션의 경우 종종 40-60분), 그리고 제한된 처리량(초당 약 7건의 트랜잭션). 이러한 한계로 인해 작업 증명은 빠른 결제와 높은 트랜잭션 볼륨이 필요한 많은 결제 시스템 응용에 적합하지 않다.
Ripple Protocol Consensus Algorithm
Ripple प्रोटोकॉल सहमति एल्गोरिदम (RPCA) प्रत्येक सर्वर द्वारा उन सभी वैध लेनदेन को लेकर शुरू होता है जो उसने देखे हैं और जो अभी तक कैंडिडेट लेनदेन के रूप में लागू नहीं किए गए हैं। सर्वर फिर एक बहु-दौर प्रोटोकॉल का पालन करते हैं जहां वे वर्तमान लेजर पर लागू किए जाने वाले लेनदेन के एक सेट पर सहमति की ओर पुनरावृत्त रूप से काम करते हैं। प्रत्येक दौर में, सर्वर उन लेनदेन से युक्त प्रस्ताव बनाते हैं जिन्हें वे अगले लेजर में शामिल किया जाना चाहिए।
प्रत्येक सहमति दौर के दौरान, सर्वर अपने Unique Node List (UNL) में अन्य सर्वरों को अपने प्रस्ताव संप्रेषित करते हैं। सर्वर तब गणना करते हैं कि कौन से लेनदेन प्रस्तावों के एक सीमा प्रतिशत में दिखाई देते हैं। शुरू में, यह सीमा 50% पर निर्धारित होती है, जिसका अर्थ है कि एक लेनदेन को अगले दौर के लिए विचार किए जाने हेतु सर्वर की UNL के कम से कम आधे प्रस्तावों में दिखाई देना चाहिए। जैसे-जैसे सहमति क्रमिक दौरों के माध्यम से आगे बढ़ती है, यह सीमा क्रमिक रूप से बढ़ती है (आमतौर पर 60%, 70%, और अंत में 80%)।
जब कोई लेनदेन सर्वर की UNL में 80% समर्थन की सुपरमेजॉरिटी सीमा प्राप्त करता है, तो इसे अंतिम सहमति दौर के लिए उस सर्वर के प्रस्ताव में शामिल किया जाता है। नेटवर्क भर में इस सीमा तक पहुंचने वाले सभी लेनदेन लेजर पर लागू किए जाते हैं, जिसे फिर क्रिप्टोग्राफिक रूप से हैश और हस्ताक्षरित किया जाता है। यह नव सत्यापित लेजर अंतिम-बंद लेजर बन जाता है, और प्रक्रिया कैंडिडेट लेनदेन के अगले सेट के साथ फिर से शुरू होती है।
सहमति प्रक्रिया आमतौर पर 5 सेकंड या उससे कम में पूरी होती है, अधिकांश लेनदेन को सुपरमेजॉरिटी सीमा प्राप्त करने के लिए केवल एक सहमति दौर की आवश्यकता होती है। एक दौर में सहमति प्राप्त नहीं करने वाले लेनदेन बाद के दौरों के लिए कैंडिडेट बने रहते हैं। यह डिज़ाइन सुनिश्चित करता है कि नेटवर्क मजबूत सुरक्षा गारंटी बनाए रखते हुए निरंतर प्रगति करता है, क्योंकि कोई भी लेनदेन विश्वसनीय वैलिडेटरों के सुपरमेजॉरिटी समर्थन के बिना लेजर पर लागू नहीं किया जा सकता।
Ripple Protocol Consensus Algorithm
Ripple 프로토콜 합의 알고리즘(RPCA)은 각 서버가 아직 적용되지 않은 유효한 트랜잭션을 모두 후보 트랜잭션으로 수집하는 것으로 시작한다. 그런 다음 서버들은 현재 원장에 적용할 트랜잭션 집합에 대한 합의를 향해 반복적으로 작업하는 다중 라운드 프로토콜을 따른다. 각 라운드에서 서버들은 다음 원장에 포함되어야 한다고 생각하는 트랜잭션으로 구성된 제안을 만든다.
각 합의 라운드 동안 서버들은 자신의 고유 노드 목록(UNL)에 있는 다른 서버들에게 제안을 전달한다. 그런 다음 서버들은 어떤 트랜잭션이 임계값 비율 이상의 제안에 나타나는지 계산한다. 처음에 이 임계값은 50%로 설정되며, 이는 트랜잭션이 다음 라운드에서 고려되려면 서버 UNL의 최소 절반 이상의 제안에 나타나야 함을 의미한다. 합의가 연속적인 라운드를 거치면서 이 임계값은 점진적으로 증가한다(일반적으로 60%, 70%, 그리고 최종적으로 80%).
트랜잭션이 서버의 UNL에서 80%의 절대다수 지지 임계값을 달성하면, 해당 트랜잭션은 최종 합의 라운드에 대한 서버의 제안에 포함된다. 네트워크 전체에서 이 임계값에 도달한 모든 트랜잭션은 원장에 적용되고, 원장은 암호화 해시되고 서명된다. 이 새로 검증된 원장이 마지막으로 폐쇄된 원장이 되며, 다음 후보 트랜잭션 집합으로 프로세스가 다시 시작된다.
합의 과정은 일반적으로 5초 이내에 완료되며, 대부분의 트랜잭션은 절대다수 임계값을 달성하기 위해 단 한 번의 합의 라운드만 필요로 한다. 한 라운드에서 합의를 달성하지 못한 트랜잭션은 후속 라운드의 후보로 남는다. 이 설계는 신뢰할 수 있는 검증자들의 절대다수 지지 없이는 어떤 트랜잭션도 원장에 적용될 수 없으므로 강력한 안전성 보장을 유지하면서 네트워크가 지속적으로 진행되도록 보장한다.
Formal Analysis of Convergence
RPCA की शुद्धता नेटवर्क में विभिन्न नोड्स द्वारा चुनी गई UNL के बीच ओवरलैप पर गंभीर रूप से निर्भर करती है। UNL_i को नोड i की unique node list और UNL_i ∩ UNL_j को UNL_i और UNL_j दोनों में दिखाई देने वाले नोड्स के सेट के रूप में मानें। नेटवर्क को सहमति बनाए रखने के लिए, हम आवश्यक करते हैं कि किन्हीं भी दो नोड्स i और j के लिए, उनके UNL का प्रतिच्छेदन किसी भी UNL के अधिकतम आकार के सापेक्ष पर्याप्त रूप से बड़ा होना चाहिए।
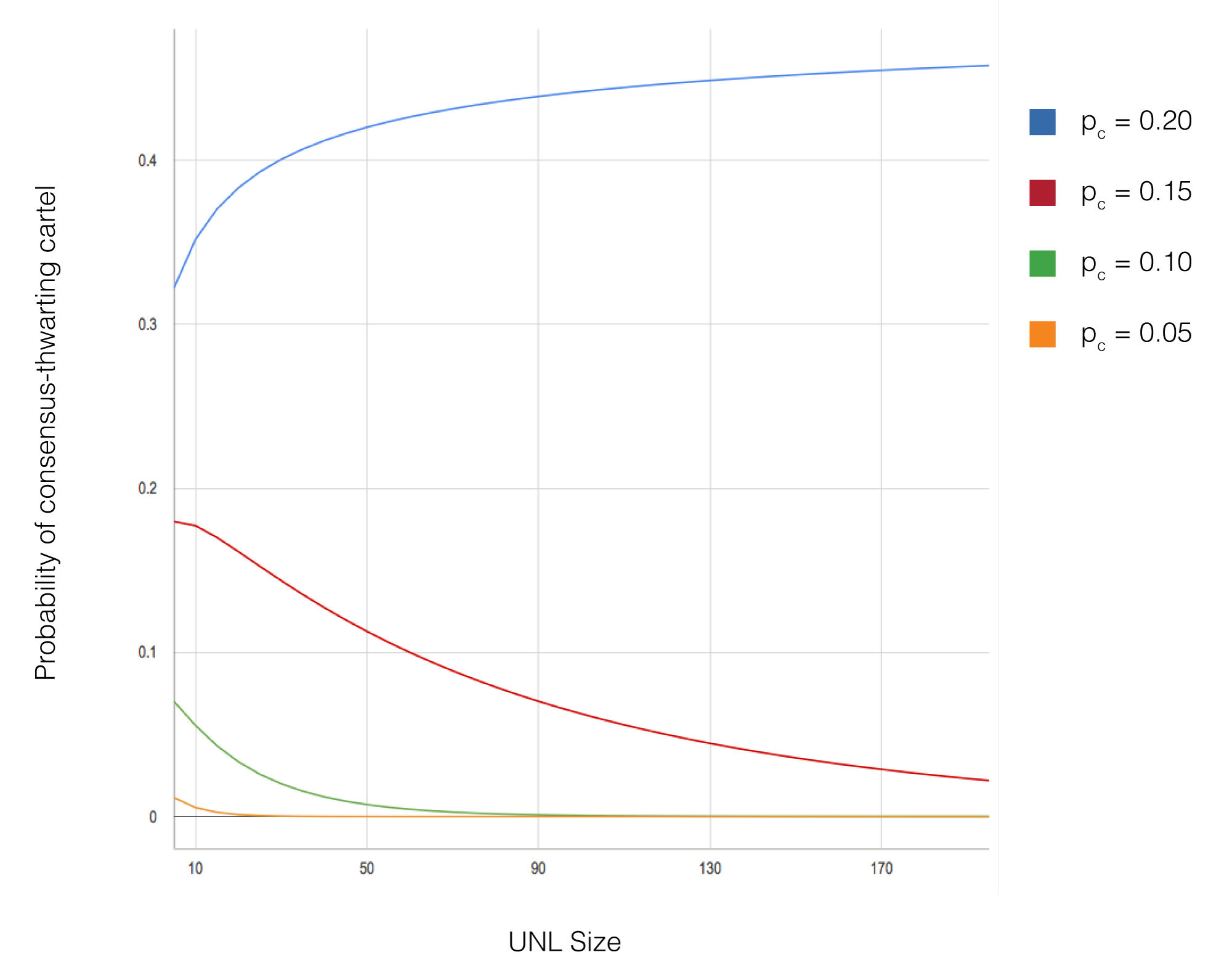
विशेष रूप से, प्रोटोकॉल सुरक्षा की गारंटी देता है जब |UNL_i ∩ UNL_j| / max(|UNL_i|, |UNL_j|) 1/5 सभी नोड जोड़ियों i और j के लिए। यह शर्त सुनिश्चित करती है कि भले ही Byzantine नोड्स नेटवर्क के विभिन्न भागों को अलग-अलग सहमति निर्णय लेने का कारण बनाने का प्रयास करें, विश्वसनीय नोड्स का ओवरलैप फोर्क को रोकता है। यदि यह शर्त पूरी होती है और किसी भी UNL में 1/5 से कम नोड्स Byzantine हैं, तो सभी सही नोड्स एक ही सहमति निर्णय पर पहुंचेंगे।
औपचारिक प्रमाण यह दिखाकर आगे बढ़ता है कि यदि दो नोड्स अलग-अलग सहमति निर्णय ले सकते, तो कोई लेनदेन T अवश्य होना चाहिए जो एक नोड के अंतिम लेजर में दिखाई देता है लेकिन दूसरे में नहीं। इसके लिए, T को पहले नोड की UNL में 80% समर्थन प्राप्त होना चाहिए लेकिन दूसरे नोड की UNL में 80% से कम समर्थन। हालांकि, ओवरलैप आवश्यकता और Byzantine नोड्स पर बाधा को देखते हुए, यह दिखाया जा सकता है कि यह परिदृश्य असंभव है: यदि T UNL_i में 80% समर्थन प्राप्त करता है, तो इसे ओवरलैप शर्त को संतुष्ट करने वाली किसी भी UNL_j में कम से कम 60% समर्थन प्राप्त करना चाहिए, और सहमति के पर्याप्त दौरों के साथ, यह 80% में अभिसरित होगा या दोनों नोड्स द्वारा अस्वीकार किया जाएगा।
जीवंतता गुण -- कि सहमति अंततः प्राप्त होगी -- इस अवलोकन से अनुसरण करता है कि शामिल करने की सीमा सहमति दौरों के माध्यम से नियतात्मक रूप से बढ़ती है। Byzantine नोड्स और नेटवर्क विलंब की उपस्थिति में भी, प्रोटोकॉल सुनिश्चित करता है कि ईमानदार नोड्स के सुपरमेजॉरिटी द्वारा समर्थित लेनदेन अंततः शामिल किए जाएंगे, जबकि ऐसे समर्थन की कमी वाले लेनदेन बाहर रखे जाएंगे। सहमति के लिए सीमित समय (आमतौर पर 5 सेकंड) भुगतान प्रणाली अनुप्रयोगों के लिए उपयुक्त व्यावहारिक जीवंतता गारंटी प्रदान करता है।
Formal Analysis of Convergence
RPCA의 정확성은 네트워크 내 서로 다른 노드들이 선택한 UNL 간의 중첩에 결정적으로 의존한다. UNL_i를 노드 i의 고유 노드 목록이라 하고, UNL_i ∩ UNL_j를 UNL_i와 UNL_j 양쪽에 나타나는 노드 집합이라 하자. 네트워크가 합의를 유지하기 위해서는 임의의 두 노드 i와 j에 대해, 그들의 UNL의 교집합이 어느 쪽 UNL의 최대 크기에 비해 충분히 커야 한다.
구체적으로, 프로토콜은 모든 노드 쌍 i와 j에 대해 |UNL_i ∩ UNL_j| / max(|UNL_i|, |UNL_j|) 1/5일 때 안전성을 보장한다. 이 조건은 Byzantine 노드가 네트워크의 다른 부분들이 서로 다른 합의 결정에 도달하게 하려고 시도하더라도, 신뢰 노드의 중첩이 포크를 방지하도록 보장한다. 이 조건이 성립하고 어떤 UNL에서든 1/5 미만의 노드가 Byzantine이면, 모든 올바른 노드는 동일한 합의 결정에 도달할 것이다.
형식적 증명은 두 노드가 서로 다른 합의 결정에 도달할 수 있다면, 한 노드의 최종 원장에는 나타나지만 다른 노드에는 나타나지 않는 어떤 트랜잭션 T가 존재해야 함을 보여줌으로써 진행된다. 이것이 발생하려면, T가 첫 번째 노드의 UNL에서 80%의 지지를 달성했지만 두 번째 노드의 UNL에서는 80% 미만의 지지를 받아야 한다. 그러나 중첩 요구사항과 Byzantine 노드에 대한 제약을 고려하면, 이 시나리오가 불가능함을 보일 수 있다: T가 UNL_i에서 80%의 지지를 달성하면, 중첩 조건을 만족하는 어떤 UNL_j에서도 최소 60%의 지지를 달성해야 하며, 충분한 합의 라운드를 거치면 80%로 수렴하거나 양쪽 노드에 의해 거부될 것이다.
활성 속성 -- 합의가 결국 도달된다는 것 -- 은 포함을 위한 임계값이 합의 라운드를 통해 결정론적으로 증가한다는 관찰에서 따른다. Byzantine 노드와 네트워크 지연이 존재하더라도, 프로토콜은 정직한 노드의 절대다수가 지지하는 트랜잭션은 결국 포함되고, 그러한 지지가 부족한 트랜잭션은 제외되도록 보장한다. 합의에 대한 제한된 시간(일반적으로 5초)은 결제 시스템 응용에 적합한 실용적인 활성 보장을 제공한다.
Unique Node Lists
Unique Node List (UNL) RPCA का एक मूलभूत घटक है जो इसे अन्य सहमति एल्गोरिदम से अलग करता है। Ripple नेटवर्क में प्रत्येक नोड एक UNL बनाए रखता है जिसमें अन्य नोड्स शामिल होते हैं जिन पर वह नेटवर्क को धोखा देने के लिए मिलीभगत न करने का भरोसा करता है। महत्वपूर्ण रूप से, यह विश्वास वैश्विक के बजाय स्थानीय है: विभिन्न नोड्स की अलग-अलग UNL हो सकती हैं, और वैलिडेटरों के विश्व स्तर पर सहमत सेट की कोई आवश्यकता नहीं है। यह डिज़ाइन नेटवर्क को विकेंद्रीकरण बनाए रखते हुए स्वाभाविक रूप से बढ़ने की अनुमति देता है।
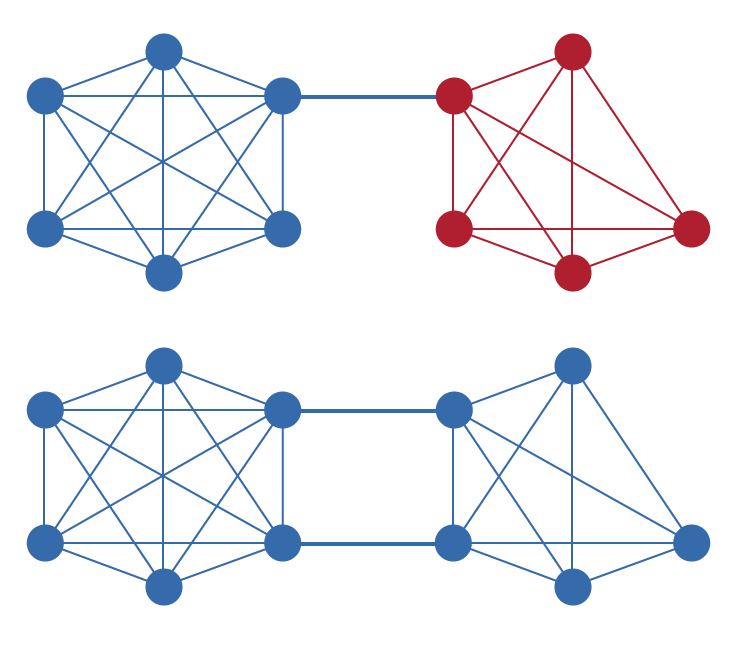
UNL प्रूफ-ऑफ-वर्क की आवश्यकता के बिना Sybil हमला रोकथाम तंत्र के रूप में कार्य करता है। एक भोले मतदान प्रणाली में, एक हमलावर असमानुपातिक प्रभाव प्राप्त करने के लिए कई छद्मनामी नोड्स बना सकता है। प्रत्येक नोड से स्पष्ट रूप से यह चुनने की आवश्यकता करके कि वह किन अन्य नोड्स पर भरोसा करता है, RPCA सुनिश्चित करता है कि अतिरिक्त पहचान बनाने से कोई लाभ नहीं होता जब तक कि वे पहचान मौजूदा नोड्स को अपनी UNL में जोड़ने के लिए मना नहीं सकतीं। यह Sybil प्रतिरोध की समस्या को कम्प्यूटेशनल व्यय से प्रतिष्ठा और विश्वास संबंधों में स्थानांतरित करता है।
नेटवर्क को सही ढंग से कार्य करने के लिए, UNL को इस प्रकार चुना जाना चाहिए कि उनमें पर्याप्त ओवरलैप हो, जैसा कि औपचारिक विश्लेषण में वर्णित है। व्यवहार में, इसका अर्थ है कि जहां प्रत्येक नोड ऑपरेटर को अपनी UNL चुनने में स्वायत्तता है, उन्हें यह सुनिश्चित करना होगा कि उनकी सूची में ऐसे वैलिडेटर शामिल हैं जिन पर नेटवर्क के अन्य भागों द्वारा भी भरोसा किया जाता है। Ripple विविध संस्थाओं द्वारा संचालित वैलिडेटरों से युक्त एक डिफ़ॉल्ट UNL प्रदान करता है, लेकिन नोड ऑपरेटर अपने स्वयं के विश्वास मूल्यांकन के आधार पर इस सूची को संशोधित करने के लिए स्वतंत्र हैं।
UNL तंत्र प्रगतिशील विकेंद्रीकरण की ओर एक स्वाभाविक मार्ग भी प्रदान करता है। नेटवर्क के प्रारंभिक चरणों में, स्थिरता और विश्वसनीयता सुनिश्चित करने के लिए वैलिडेटरों का एक अधिक केंद्रीकृत सेट उपयुक्त हो सकता है। जैसे-जैसे नेटवर्क परिपक्व होता है और अधिक विविध ऑपरेटर अपनी विश्वसनीयता प्रदर्शित करते हैं, UNL वैलिडेटरों के एक व्यापक सेट को शामिल करने के लिए विकसित हो सकते हैं, जिससे इसकी सुरक्षा गुणों से समझौता किए बिना नेटवर्क की लचीलापन और विकेंद्रीकरण बढ़ता है।
Unique Node Lists
고유 노드 목록(UNL)은 RPCA를 다른 합의 알고리즘과 구별하는 근본적인 구성 요소이다. Ripple 네트워크의 각 노드는 네트워크를 속이기 위해 공모하지 않을 것으로 신뢰하는 다른 노드들로 구성된 UNL을 유지한다. 중요한 점은 이 신뢰가 전역적이 아닌 지역적이라는 것이다: 서로 다른 노드가 서로 다른 UNL을 가질 수 있으며, 전역적으로 합의된 검증자 집합을 요구하지 않는다. 이 설계는 탈중앙화를 유지하면서 네트워크가 유기적으로 확장될 수 있게 한다.
UNL은 작업 증명 없이 Sybil 공격 방지 메커니즘 역할을 한다. 순진한 투표 시스템에서 공격자는 불균형적인 영향력을 얻기 위해 많은 가명 노드를 생성할 수 있다. 각 노드가 신뢰하는 다른 노드를 명시적으로 선택하도록 요구함으로써, RPCA는 해당 신원이 기존 노드를 설득하여 UNL에 추가될 수 없는 한, 추가 신원을 생성하는 것이 아무런 이점을 제공하지 않도록 보장한다. 이것은 Sybil 저항의 문제를 계산적 지출에서 평판과 신뢰 관계로 전환시킨다.
네트워크가 올바르게 기능하기 위해서는 형식적 분석에서 설명한 것처럼 UNL이 충분한 중첩을 갖도록 선택되어야 한다. 실제로 이것은 각 노드 운영자가 UNL 선택에 자율성을 가지면서도 네트워크의 다른 부분에서도 신뢰하는 검증자를 포함하도록 보장해야 함을 의미한다. Ripple은 다양한 주체가 운영하는 검증자로 구성된 기본 UNL을 제공하지만, 노드 운영자는 자체 신뢰 평가에 따라 이 목록을 자유롭게 수정할 수 있다.
UNL 메커니즘은 또한 점진적 탈중앙화를 향한 자연스러운 경로를 제공한다. 네트워크 초기 단계에서는 안정성과 신뢰성을 보장하기 위해 보다 중앙화된 검증자 집합이 적절할 수 있다. 네트워크가 성숙하고 더 다양한 운영자들이 신뢰성을 입증함에 따라, UNL은 보안 속성을 타협하지 않으면서 네트워크의 회복력과 탈중앙화를 높이는 더 넓은 검증자 집합을 포함하도록 진화할 수 있다.
Simulation Code
RPCA के सैद्धांतिक विश्लेषण को मान्य करने और विभिन्न स्थितियों में इसके प्रदर्शन का मूल्यांकन करने के लिए, कस्टम-निर्मित सिमुलेशन सॉफ्टवेयर का उपयोग करके व्यापक सिमुलेशन आयोजित किए गए। सिमुलेशन फ्रेमवर्क नोड्स के एक नेटवर्क का मॉडल बनाता है, जिनमें से प्रत्येक अपना स्वयं का UNL बनाए रखता है और सहमति प्रोटोकॉल में भाग लेता है। कोड पूर्ण RPCA एल्गोरिदम को लागू करता है, जिसमें लेनदेन प्रस्ताव, बढ़ते सीमा मानों के साथ मतदान दौर और लेजर सत्यापन शामिल हैं।
सिमुलेशन में विविध किए गए प्रमुख पैरामीटरों में नेटवर्क आकार (10 से 1,000 नोड्स तक), Byzantine नोड्स का प्रतिशत (0% से 20% तक), UNL आकार (आमतौर पर 5 से 50 नोड्स के बीच) और नेटवर्क टोपोलॉजी कॉन्फ़िगरेशन शामिल हैं। प्रत्येक पैरामीटर कॉन्फ़िगरेशन के लिए, परिणामों की सांख्यिकीय वैधता सुनिश्चित करने के लिए विभिन्न यादृच्छिक बीजों के साथ कई सिमुलेशन रन आयोजित किए गए। सिमुलेशन ने सहमति विलंबता, फोर्क संभावना और लेनदेन थ्रूपुट सहित मेट्रिक्स को ट्रैक किया।
सिमुलेशन परिणाम अभिसरण और सुरक्षा के संबंध में सैद्धांतिक भविष्यवाणियों की पुष्टि करते हैं। सभी कॉन्फ़िगरेशन जहां UNL ओवरलैप शर्त संतुष्ट थी और Byzantine नोड्स प्रत्येक UNL के 20% से कम थे, नेटवर्क ने बिना फोर्क के सफलतापूर्वक सहमति प्राप्त की। सहमति विलंबता नेटवर्क आकार की परवाह किए बिना लगातार कम रही (आमतौर पर 3-5 सिमुलेटेड सेकंड में पूरी), जो एल्गोरिदम की स्केलेबिलिटी प्रदर्शित करती है। 15% Byzantine नोड्स सक्रिय रूप से सहमति को बाधित करने का प्रयास करने पर भी, जब तक UNL ओवरलैप आवश्यकता पूरी होती रही, नेटवर्क ने शुद्धता बनाए रखी।
अतिरिक्त सिमुलेशन ने एज केस और विफलता परिदृश्यों का पता लगाया, जिनमें नेटवर्क विभाजन, UNL संरचना में अचानक परिवर्तन और Byzantine नोड्स द्वारा समन्वित हमले शामिल हैं। इन सिमुलेशन ने प्रोटोकॉल की मजबूती के बारे में अंतर्दृष्टि प्रदान की और UNL चयन और नेटवर्क संचालन के लिए अनुशंसित सर्वोत्तम प्रथाओं की जानकारी दी। स्वतंत्र सत्यापन और आगे के अनुसंधान की अनुमति देने के लिए पूर्ण सिमुलेशन कोड उपलब्ध कराया गया है।
Simulation Code
RPCA의 이론적 분석을 검증하고 다양한 조건에서의 성능을 평가하기 위해, 맞춤 제작된 시뮬레이션 소프트웨어를 사용하여 광범위한 시뮬레이션이 수행되었다. 시뮬레이션 프레임워크는 각자의 UNL을 유지하고 합의 프로토콜에 참여하는 노드 네트워크를 모델링한다. 코드는 트랜잭션 제안, 임계값이 증가하는 투표 라운드, 원장 검증을 포함한 전체 RPCA 알고리즘을 구현한다.
시뮬레이션에서 변경된 주요 매개변수에는 네트워크 크기(10에서 1,000개의 노드), Byzantine 노드 비율(0%에서 20%), UNL 크기(일반적으로 5에서 50개의 노드), 그리고 네트워크 토폴로지 구성이 포함된다. 각 매개변수 구성에 대해 결과의 통계적 유효성을 보장하기 위해 서로 다른 무작위 시드를 사용하여 여러 시뮬레이션 실행이 수행되었다. 시뮬레이션은 합의 지연 시간, 포크 확률, 트랜잭션 처리량을 포함한 메트릭을 추적하였다.
시뮬레이션 결과는 수렴과 안전성에 관한 이론적 예측을 확인한다. UNL 중첩 조건이 만족되고 Byzantine 노드가 각 UNL의 20% 미만을 차지하는 모든 구성에서, 네트워크는 포크 없이 성공적으로 합의에 도달하였다. 합의 지연 시간은 네트워크 크기에 관계없이 일관되게 낮게 유지되어(일반적으로 3-5초 시뮬레이션 시간 내에 완료), 알고리즘의 확장성을 입증하였다. 합의를 방해하려고 적극적으로 시도하는 15%의 Byzantine 노드가 있는 경우에도, UNL 중첩 요구사항이 충족되는 한 네트워크는 정확성을 유지하였다.
추가 시뮬레이션은 네트워크 분할, UNL 구성의 갑작스러운 변경, Byzantine 노드의 조직적 공격을 포함한 엣지 케이스와 실패 시나리오를 탐구하였다. 이러한 시뮬레이션은 프로토콜의 견고성에 대한 통찰을 제공하고 UNL 선택 및 네트워크 운영에 대한 권장 모범 사례를 알려주었다. 독립적인 검증과 추가 연구를 가능하게 하기 위해 전체 시뮬레이션 코드가 공개되었다.
Discussion
Bitcoin के proof-of-work सहमति की तुलना में, RPCA भुगतान प्रणाली अनुप्रयोगों के लिए कई महत्वपूर्ण फायदे प्रदान करता है। सबसे उल्लेखनीय रूप से, सहमति विलंबता 40-60 मिनट (उच्च-मूल्य Bitcoin लेनदेन के लिए आमतौर पर अनुशंसित समय) से घटाकर लगभग 5 सेकंड कर दी गई है। यह सुधार RPCA को पॉइंट-ऑफ-सेल और अन्य अनुप्रयोगों के लिए उपयुक्त बनाता है जहां लगभग तत्काल निपटान की आवश्यकता होती है। इसके अतिरिक्त, RPCA को proof-of-work की तुलना में न्यूनतम कम्प्यूटेशनल संसाधनों की आवश्यकता होती है, जो Bitcoin माइनिंग से जुड़ी भारी ऊर्जा खपत को समाप्त करता है।
हालांकि, ये फायदे विभिन्न विश्वास धारणाओं के साथ आते हैं। जबकि Bitcoin की सुरक्षा केवल इस धारणा पर निर्भर करती है कि कोई भी हमलावर नेटवर्क की 50% से अधिक कम्प्यूटेशनल शक्ति को नियंत्रित नहीं करता, RPCA के लिए आवश्यक है कि नोड्स पर्याप्त ओवरलैप वाली UNL चुनें और Byzantine नोड्स इन UNL के भीतर सीमा से अधिक न हों। यह कुछ जिम्मेदारी नोड ऑपरेटरों पर स्थानांतरित करता है कि वे विवेकपूर्ण विश्वास निर्णय लें। व्यवहार में, यह समझौता कई भुगतान प्रणाली उपयोग मामलों के लिए स्वीकार्य है जहां भाग लेने वाली संस्थाओं के मौजूदा विश्वास संबंध हैं।
नेटवर्क टोपोलॉजी और UNL चयन रणनीति सहमति प्रणाली के गुणों को महत्वपूर्ण रूप से प्रभावित करती है। एक अत्यधिक केंद्रीकृत टोपोलॉजी जहां सभी नोड्स अपनी UNL में समान वैलिडेटर शामिल करते हैं, सुरक्षा को अधिकतम करती है लेकिन उन वैलिडेटरों के अनुपलब्ध होने पर जीवंतता कम कर सकती है। इसके विपरीत, न्यूनतम UNL ओवरलैप वाली अत्यधिक विकेंद्रीकृत टोपोलॉजी जीवंतता में सुधार कर सकती है लेकिन ओवरलैप बहुत कम होने पर सहमति विफलताओं का जोखिम उठा सकती है। इष्टतम संतुलन खोजने के लिए विशिष्ट तैनाती परिदृश्य और जोखिम सहनशीलता पर सावधानीपूर्वक विचार की आवश्यकता होती है।
भविष्य का कार्य अनुकूली UNL चयन एल्गोरिदम का पता लगा सकता है जो विकेंद्रीकरण को अधिकतम करते हुए स्वचालित रूप से ओवरलैप आवश्यकताओं को बनाए रखते हैं, नोड्स के लिए देखे गए वैलिडेटर व्यवहार के आधार पर अपनी UNL को गतिशील रूप से समायोजित करने के तंत्र, और सहमति एल्गोरिदम के विस्तार जो Byzantine नोड्स के और भी अधिक प्रतिशत को सहन कर सकते हैं। ये सुधार बड़े पैमाने पर वितरित भुगतान प्रणालियों के लिए RPCA की मजबूती और प्रयोज्यता को और बढ़ा सकते हैं।
Discussion
비트코인의 작업 증명 합의와 비교하여, RPCA는 결제 시스템 응용에 여러 가지 중요한 이점을 제공한다. 가장 주목할 만한 것은 합의 지연 시간이 40-60분(고가치 비트코인 트랜잭션에 일반적으로 권장되는 시간)에서 약 5초로 단축된다는 점이다. 이 개선으로 RPCA는 즉각적인 결제가 필요한 판매 시점(POS) 및 기타 응용에 적합해진다. 또한 RPCA는 작업 증명에 비해 최소한의 계산 자원을 필요로 하여, 비트코인 채굴과 관련된 막대한 에너지 소비를 제거한다.
그러나 이러한 장점에는 다른 신뢰 가정이 수반된다. 비트코인의 보안이 어떤 공격자도 네트워크 계산 능력의 50% 이상을 통제하지 못한다는 가정에만 의존하는 반면, RPCA는 노드들이 충분한 중첩을 가진 UNL을 선택하고 Byzantine 노드가 이 UNL 내에서 임계값을 초과하지 않을 것을 요구한다. 이것은 노드 운영자에게 신중한 신뢰 결정을 내릴 일부 책임을 전가한다. 실제로 이 절충은 참여 기관이 기존의 신뢰 관계를 가진 많은 결제 시스템 사용 사례에서 수용 가능하다.
네트워크 토폴로지와 UNL 선택 전략은 합의 시스템의 속성에 상당한 영향을 미친다. 모든 노드가 UNL에 동일한 검증자를 포함하는 고도로 중앙화된 토폴로지는 안전성을 최대화하지만, 해당 검증자가 사용 불가능해지면 활성이 감소할 수 있다. 반대로, 최소한의 UNL 중첩을 가진 고도로 탈중앙화된 토폴로지는 활성을 개선할 수 있지만, 중첩이 너무 희박해지면 합의 실패의 위험이 있다. 최적의 균형을 찾으려면 특정 배포 시나리오와 위험 허용 범위를 신중하게 고려해야 한다.
향후 연구는 탈중앙화를 최대화하면서 중첩 요구사항을 자동으로 유지하는 적응적 UNL 선택 알고리즘, 관찰된 검증자 행동에 기반하여 노드가 동적으로 UNL을 조정하는 메커니즘, 그리고 더 높은 비율의 Byzantine 노드를 허용할 수 있는 합의 알고리즘의 확장을 탐구할 수 있다. 이러한 개선은 대규모 분산 결제 시스템에 대한 RPCA의 견고성과 적용 가능성을 더욱 향상시킬 수 있다.
Conclusion
Ripple प्रोटोकॉल सहमति एल्गोरिदम भुगतान प्रणालियों के लिए वितरित सहमति में एक महत्वपूर्ण प्रगति का प्रतिनिधित्व करता है। सभी नोड्स के बीच वैश्विक सहमति की आवश्यकता के बजाय सामूहिक रूप से विश्वसनीय उप-नेटवर्क का उपयोग करके, RPCA Byzantine विफलताओं के खिलाफ मजबूत गारंटी बनाए रखते हुए सेकंडों में सहमति प्राप्त करता है। औपचारिक विश्लेषण प्रदर्शित करता है कि जब तक UNL पर्याप्त ओवरलैप के साथ चुनी जाती हैं और Byzantine नोड्स सीमा से नीचे रहते हैं, नेटवर्क बिना फोर्क के सही सहमति प्राप्त करेगा।
इस कार्य के व्यावहारिक निहितार्थ Ripple भुगतान नेटवर्क से परे फैलते हैं। RPCA प्रदर्शित करता है कि सहमति विलंबता और सुरक्षा गारंटी के बीच पारंपरिक समझौते को सावधानीपूर्वक प्रोटोकॉल डिज़ाइन और स्थानीय विश्वास संबंधों के उपयोग के माध्यम से दूर किया जा सकता है। यह दृष्टिकोण अन्य वितरित प्रणालियों पर लागू हो सकता है जहां कम विलंबता महत्वपूर्ण है और प्रतिभागियों के मौजूदा विश्वास संबंध हैं, जैसे अंतर-बैंक निपटान प्रणालियां, आपूर्ति श्रृंखला ट्रैकिंग और अन्य वित्तीय अवसंरचना अनुप्रयोग।
उत्पादन प्रणालियों में RPCA की तैनाती ने एल्गोरिदम की प्रदर्शन विशेषताओं और मजबूती को मान्य किया है। Ripple नेटवर्क 3-5 सेकंड की लगातार सहमति विलंबता के साथ प्रति सेकंड हजारों लेनदेन संसाधित करता है, जो प्रदर्शित करता है कि सैद्धांतिक गुण वास्तविक-विश्व संचालन में प्रभावी रूप से अनुवादित होते हैं। जैसे-जैसे नेटवर्क विकसित होना और विविध ऑपरेटरों से अतिरिक्त वैलिडेटर शामिल करना जारी रखता है, यह एक व्यावहारिक उदाहरण प्रदान करता है कि कैसे एक विकेंद्रीकृत सहमति प्रणाली बड़े पैमाने पर सुरक्षा और प्रदर्शन दोनों बनाए रख सकती है।
Conclusion
Ripple 프로토콜 합의 알고리즘은 결제 시스템을 위한 분산 합의에서 중요한 발전을 나타낸다. 모든 노드 간의 전역적 합의를 요구하는 대신 집합적으로 신뢰할 수 있는 하위 네트워크를 활용함으로써, RPCA는 Byzantine 장애에 대한 강력한 보장을 유지하면서 수 초 만에 합의를 달성한다. 형식적 분석은 UNL이 충분한 중첩으로 선택되고 Byzantine 노드가 임계값 이하로 유지되는 한, 네트워크가 포크 없이 올바른 합의에 도달할 것임을 입증한다.
이 연구의 실질적인 시사점은 Ripple 결제 네트워크를 넘어 확장된다. RPCA는 합의 지연 시간과 보안 보장 사이의 전통적인 절충이 신중한 프로토콜 설계와 지역적 신뢰 관계의 사용을 통해 극복될 수 있음을 보여준다. 이 접근 방식은 낮은 지연 시간이 중요하고 참가자들이 기존의 신뢰 관계를 가진 다른 분산 시스템, 예를 들어 은행 간 결제 시스템, 공급망 추적, 기타 금융 인프라 응용에 적용 가능할 수 있다.
프로덕션 시스템에서 RPCA의 배포는 알고리즘의 성능 특성과 견고성을 검증하였다. Ripple 네트워크는 일관된 3-5초의 합의 지연 시간으로 초당 수천 건의 트랜잭션을 처리하며, 이론적 속성이 실제 운영에 효과적으로 번역됨을 입증한다. 네트워크가 계속 발전하고 다양한 운영자의 추가 검증자를 통합함에 따라, 탈중앙화된 합의 시스템이 대규모에서 보안과 성능을 모두 유지할 수 있는 방법의 실용적인 사례를 제공한다.
References
Lamport, L., Shostak, R., and Pease, M. (1982). "The Byzantine Generals Problem." ACM Transactions on Programming Languages and Systems, 4(3):382-401. इस मौलिक पत्र ने दोषपूर्ण घटकों वाली वितरित प्रणालियों में सहमति प्राप्त करने की समस्या को औपचारिक रूप दिया और Byzantine दोष-सहिष्णु प्रणालियों के लिए सैद्धांतिक आधार स्थापित किया।
Castro, M., and Liskov, B. (1999). "Practical Byzantine Fault Tolerance." Proceedings of the Third Symposium on Operating Systems Design and Implementation (OSDI). इस कार्य ने PBFT पेश किया, यह प्रदर्शित करते हुए कि Byzantine दोष सहिष्णुता व्यावहारिक प्रदर्शन के साथ प्राप्त की जा सकती है, हालांकि O(n^2) संचार जटिलता स्केलेबिलिटी को सीमित करती है।
Nakamoto, S. (2008). "Bitcoin: A Peer-to-Peer Electronic Cash System." इस श्वेतपत्र ने डिजिटल मुद्रा में दोहरे खर्च की समस्या के समाधान के रूप में proof-of-work सहमति पेश की, जो उच्च विलंबता और ऊर्जा खपत की कीमत पर विश्वसनीय पक्षों के बिना विकेंद्रीकृत सहमति को सक्षम बनाती है।
Lamport, L. (1998). "The Part-Time Parliament." ACM Transactions on Computer Systems, 16(2):133-169. इस पत्र ने Paxos एल्गोरिदम प्रस्तुत किया, जो क्रैश विफलताओं के तहत असमकालिक प्रणालियों में सहमति प्राप्त करता है, जिसने बाद के सहमति प्रोटोकॉल डिज़ाइनों को प्रभावित किया।
Fischer, M. J., Lynch, N. A., and Paterson, M. S. (1985). "Impossibility of Distributed Consensus with One Faulty Process." Journal of the ACM, 32(2):374-382. FLP असंभवता परिणाम ने असमकालिक प्रणालियों में सहमति एल्गोरिदम क्या प्राप्त कर सकते हैं इसकी मूलभूत सीमाएं स्थापित कीं, जिसने व्यावहारिक सहमति प्रोटोकॉल के लिए डिज़ाइन स्थान को आकार दिया।
References
Lamport, L., Shostak, R., and Pease, M. (1982). "The Byzantine Generals Problem." ACM Transactions on Programming Languages and Systems, 4(3):382-401. 이 기념비적 논문은 결함이 있는 구성 요소를 가진 분산 시스템에서 합의에 도달하는 문제를 공식화하고 Byzantine fault-tolerant 시스템의 이론적 기반을 확립하였다.
Castro, M., and Liskov, B. (1999). "Practical Byzantine Fault Tolerance." Proceedings of the Third Symposium on Operating Systems Design and Implementation (OSDI). 이 연구는 PBFT를 도입하여 Byzantine fault tolerance가 실용적인 성능으로 달성될 수 있음을 보여주었으나, O(n^2) 통신 복잡도가 확장성을 제한하였다.
Nakamoto, S. (2008). "Bitcoin: A Peer-to-Peer Electronic Cash System." 이 백서는 디지털 화폐에서의 이중 지불 문제에 대한 해결책으로 작업 증명 합의를 도입하여, 높은 지연 시간과 에너지 소비를 대가로 신뢰할 수 있는 당사자 없이 탈중앙화된 합의를 가능하게 하였다.
Lamport, L. (1998). "The Part-Time Parliament." ACM Transactions on Computer Systems, 16(2):133-169. 이 논문은 충돌 결함 하에서 비동기 시스템에서 합의를 달성하는 Paxos 알고리즘을 제시하여, 후속 합의 프로토콜 설계에 영향을 미쳤다.
Fischer, M. J., Lynch, N. A., and Paterson, M. S. (1985). "Impossibility of Distributed Consensus with One Faulty Process." Journal of the ACM, 32(2):374-382. FLP 불가능성 결과는 비동기 시스템에서 합의 알고리즘이 달성할 수 있는 것의 근본적 한계를 확립하여, 실용적인 합의 프로토콜의 설계 공간을 형성하였다.




