
O Algoritmo de Consenso do Protocolo Ripple
Abstract
虽然存在多种针对Byzantine Generals Problem的共识算法,特别是与分布式支付系统相关的算法,但其中许多都因网络中所有节点需要同步通信的要求而导致高延迟问题。在本研究中,我们提出了一种新颖的共识算法,通过利用更大网络内的集体信任子网络来规避这一要求。我们证明,防止Sybil攻击所需的"信任"实际上不是全局性的,而是网络中每个节点的局部性的。
Ripple协议共识算法(RPCA)由所有节点每隔几秒应用一次,以维护网络的正确性和一致性。一旦达成共识,当前账本被视为"关闭",成为最后关闭的账本(last-closed ledger)。该算法的独特之处在于,它在维持对Byzantine故障的强大保障的同时实现了低延迟共识,使其适用于实时金融结算系统。
Abstract
Embora existam vários algoritmos de consenso para o Byzantine Generals Problem, especificamente no que diz respeito a sistemas de pagamento distribuídos, muitos sofrem de alta latência induzida pelo requisito de que todos os nós dentro da rede se comuniquem de forma síncrona. Neste trabalho, apresentamos um algoritmo de consenso inovador que contorna esse requisito ao utilizar sub-redes coletivamente confiáveis dentro da rede maior. Mostramos que a "confiança" necessária para prevenir ataques Sybil não é, de fato, global, mas sim local a cada nó na rede.
O algoritmo de consenso do protocolo Ripple (RPCA) é aplicado a cada poucos segundos por todos os nós, a fim de manter a correção e o acordo da rede. Uma vez alcançado o consenso, o livro-razão atual é considerado "fechado" e se torna o último livro-razão fechado (last-closed ledger). Este algoritmo é único no sentido de que alcança consenso com baixa latência enquanto mantém fortes garantias contra falhas Byzantine, tornando-o adequado para sistemas de liquidação financeira em tempo real.
Introduction
分布式支付系统必须实现共识算法,以便在存在故障或恶意行为者的情况下及时正确地处理支付。比特币通过工作量证明(proof-of-work)来达成共识,这要求所有节点消耗计算资源来解决密码学难题。虽然这种方法提供了强大的安全保障,但它存在显著的缺点,包括高能耗、低交易吞吐量以及对于高价值交易可能延长至一小时或更长时间的确认延迟。
Ripple协议共识算法提供了一种不需要工作量证明的分布式共识新方法。取而代之的是,网络中的节点通过在几秒内达成共识的投票过程来集体同意交易集合。这种共识机制专门为全球支付网络的需求而设计,在这些网络中,低延迟和高吞吐量对于实际部署至关重要。
RPCA的关键创新在于它不要求网络中的所有节点彼此达成一致。相反,每个节点维护一个唯一节点列表(Unique Node List, UNL),其中包含它信任不会串通的其他节点。只要节点选择的UNL具有足够的重叠,且故障节点低于阈值百分比,网络就会达成共识。这种方法在以秒而非分钟或小时来衡量共识延迟的同时,提供了支付系统所需的安全保障。
Introduction
Um sistema de pagamento distribuído deve implementar um algoritmo de consenso para processar pagamentos corretamente e de maneira oportuna, mesmo na presença de atores defeituosos ou maliciosos. O Bitcoin alcança consenso usando prova de trabalho (proof-of-work), que exige que todos os nós gastem recursos computacionais resolvendo quebra-cabeças criptográficos. Embora essa abordagem forneça fortes garantias de segurança, ela sofre de desvantagens significativas, incluindo alto consumo de energia, baixa taxa de transferência de transações e longas latências de confirmação que podem se estender a uma hora ou mais para transações de alto valor.
O algoritmo de consenso do protocolo Ripple fornece uma nova abordagem para o consenso distribuído que não requer prova de trabalho. Em vez disso, os nós na rede concordam coletivamente sobre conjuntos de transações através de um processo de votação que alcança consenso em questão de segundos. Este mecanismo de consenso é projetado especificamente para os requisitos de uma rede de pagamentos global, onde baixa latência e alta taxa de transferência são essenciais para a implantação prática.
A inovação-chave no RPCA é que ele não exige que todos os nós na rede concordem entre si. Em vez disso, cada nó mantém uma Lista de Nós Únicos (Unique Node List, UNL) de outros nós em que confia para não conspirar. Desde que as UNLs escolhidas pelos nós tenham sobreposição suficiente e menos de uma porcentagem limite de nós sejam defeituosos, a rede alcançará consenso. Esta abordagem fornece as garantias de segurança necessárias para um sistema de pagamento enquanto alcança latência de consenso medida em segundos em vez de minutos ou horas.
Definition of Consensus
在分布式系统中,共识是指即使存在故障或恶意参与者,节点网络也能就共享状态达成一致的过程。共识算法必须满足三个基本属性:正确性(没有两个正确的节点做出不同的决定)、一致性(所有正确的节点达成相同的决定)和终止性(所有正确的节点最终都会做出决定)。这些属性确保分布式系统表现得如同一个单一的、可靠的节点。
达成共识的挑战源于分布式系统固有的不可靠性。节点可能崩溃,消息可能延迟或丢失,Byzantine节点可能任意或恶意地行为。Lamport、Shostak和Pease形式化的Byzantine Generals Problem捕捉了这一挑战:当一部分进程可能存在故障且通信不可靠时,一组进程如何能够达成一致?
分布式计算的经典结果确立了共识算法所能达到的基本限制。FLP不可能性结果表明,如果即使一个节点可能失败,在异步系统中没有确定性算法可以保证达成共识。因此,实用的共识算法必须在安全性(永远不会达成错误的共识)和活性(始终保持进展)之间做出权衡。比特币的工作量证明优先考虑安全性而非活性,而RPCA通过在有限时间内完成共识轮次,同时在现实的故障假设下维持强大的安全性保障,从而实现了更适合支付系统的平衡。
Definition of Consensus
Em sistemas distribuídos, consenso refere-se ao processo pelo qual uma rede de nós chega a um acordo sobre um estado compartilhado, apesar da presença de participantes defeituosos ou maliciosos. Um algoritmo de consenso deve satisfazer três propriedades fundamentais: correção (nenhum par de nós corretos decide de forma diferente), acordo (todos os nós corretos alcançam a mesma decisão) e terminação (todos os nós corretos eventualmente decidem). Essas propriedades garantem que o sistema distribuído se comporte como se fosse um nó único e confiável.
O desafio em alcançar o consenso decorre da inerente falta de confiabilidade dos sistemas distribuídos. Os nós podem falhar, as mensagens podem ser atrasadas ou perdidas, e os nós Byzantine podem se comportar de forma arbitrária ou maliciosa. O Byzantine Generals Problem, formalizado por Lamport, Shostak e Pease, captura esse desafio: como um grupo de processos pode chegar a um acordo quando alguma fração pode ser defeituosa e quando a comunicação não é confiável?
Os resultados clássicos em computação distribuída estabelecem limites fundamentais sobre o que os algoritmos de consenso podem alcançar. O resultado de impossibilidade FLP mostra que nenhum algoritmo determinístico pode garantir o consenso em um sistema assíncrono se mesmo um único nó puder falhar. Os algoritmos de consenso práticos devem, portanto, fazer compensações entre segurança (nunca alcançar um consenso incorreto) e vivacidade (sempre progredir). A prova de trabalho do Bitcoin prioriza a segurança sobre a vivacidade, enquanto o RPCA alcança um equilíbrio mais adequado para sistemas de pagamento ao completar rodadas de consenso em tempo limitado enquanto mantém fortes garantias de segurança sob suposições realistas de falha.
Existing Consensus Algorithms
已经有多种共识算法被提出来解决分布式系统中的Byzantine Generals Problem。由Castro和Liskov引入的Practical Byzantine Fault Tolerance(PBFT)算法可以在3f+1个节点的系统中容忍最多f个Byzantine故障。PBFT通过所有节点之间的多轮消息交换来达成共识,通信复杂度为O(n^2),其中n为节点数量。虽然PBFT提供了强大的安全性保障和小型网络中相对较低的延迟,但由于二次通信开销,它无法良好地扩展到大型网络。
由Lamport开发的Paxos及其变体在异步系统中提供共识,但假设的是崩溃故障而非Byzantine故障。Paxos通过一系列轮次达成共识,其中提议者建议值,接受者进行投票。虽然Paxos可以容忍任意消息延迟和进程崩溃,但处理Byzantine故障需要精心的工程设计,并且在某些场景中可能发生活锁(livelock)。
比特币的工作量证明共识算法采取了根本不同的方法,使Byzantine攻击在经济上不可行。节点竞争解决密码学难题,获胜者提议下一个交易区块。虽然这种方法可以扩展到任意网络规模并处理Byzantine故障,但它有严重的缺点:大量的能源消耗(比特币网络估计每年超过1.5亿美元)、长确认延迟(高价值交易通常为40-60分钟)以及有限的吞吐量(大约每秒7笔交易)。这些限制使得工作量证明不适合许多需要快速结算和高交易量的支付系统应用。
Existing Consensus Algorithms
Vários algoritmos de consenso foram propostos para resolver o Byzantine Generals Problem em sistemas distribuídos. O algoritmo de Practical Byzantine Fault Tolerance (PBFT), introduzido por Castro e Liskov, pode tolerar até f falhas Byzantine em um sistema de 3f+1 nós. O PBFT alcança consenso através de múltiplas rodadas de troca de mensagens entre todos os nós, com complexidade de comunicação de O(n^2), onde n é o número de nós. Embora o PBFT forneça fortes garantias de segurança e latência relativamente baixa para redes pequenas, ele não escala bem para redes grandes devido à sobrecarga de comunicação quadrática.
O Paxos e suas variantes, desenvolvidos por Lamport, fornecem consenso em sistemas assíncronos, mas assumem falhas por crash em vez de falhas Byzantine. O Paxos alcança consenso através de uma série de rodadas nas quais proponentes sugerem valores e aceitadores votam neles. Embora o Paxos possa tolerar atrasos arbitrários de mensagens e falhas de processos, ele requer engenharia cuidadosa para lidar com falhas Byzantine e pode sofrer de livelock em certos cenários.
O algoritmo de consenso por prova de trabalho do Bitcoin adota uma abordagem fundamentalmente diferente ao tornar os ataques Byzantine economicamente inviáveis. Os nós competem para resolver quebra-cabeças criptográficos, e o vencedor propõe o próximo bloco de transações. Embora essa abordagem escale para tamanhos de rede arbitrários e lide com falhas Byzantine, ela tem graves desvantagens: consumo massivo de energia (estimado em mais de 150 milhões de dólares por ano para a rede Bitcoin), longas latências de confirmação (frequentemente 40-60 minutos para transações de alto valor) e taxa de transferência limitada (aproximadamente 7 transações por segundo). Essas limitações tornam a prova de trabalho inadequada para muitas aplicações de sistemas de pagamento que exigem liquidação rápida e altos volumes de transações.
Ripple Protocol Consensus Algorithm
Ripple协议共识算法(RPCA)从每个服务器收集所有尚未应用的有效交易作为候选交易开始。然后服务器遵循多轮协议,迭代地就当前账本应用的交易集达成一致。在每一轮中,服务器提出它们认为应该包含在下一个账本中的交易提案。
在每个共识轮次中,服务器将其提案传达给唯一节点列表(UNL)中的其他服务器。然后服务器计算哪些交易出现在阈值百分比以上的提案中。最初,该阈值设置为50%,意味着交易必须出现在服务器UNL中至少一半的提案中才能被考虑进入下一轮。随着共识通过连续轮次的推进,该阈值逐步提高(通常到60%、70%,最终到80%)。
当一笔交易在服务器的UNL中达到80%的绝对多数支持阈值时,它将被包含在该服务器最终共识轮次的提案中。网络中所有达到该阈值的交易被应用到账本上,账本随后被加密哈希和签名。这个新验证的账本成为最后关闭的账本,流程以下一组候选交易重新开始。
共识过程通常在5秒或更短时间内完成,大多数交易只需要一个共识轮次即可达到绝对多数阈值。在一轮中未达成共识的交易仍作为后续轮次的候选。这种设计确保网络持续推进,同时维持强大的安全性保障,因为没有任何交易可以在没有受信任验证者绝对多数支持的情况下被应用到账本上。
Ripple Protocol Consensus Algorithm
O Algoritmo de Consenso do Protocolo Ripple (RPCA) começa com cada servidor coletando todas as transações válidas que viu e que ainda não foram aplicadas como transações candidatas. Os servidores então seguem um protocolo de múltiplas rodadas onde trabalham iterativamente em direção a um acordo sobre um conjunto de transações para aplicar ao livro-razão atual. Em cada rodada, os servidores fazem propostas consistindo nas transações que acreditam que devem ser incluídas no próximo livro-razão.
Durante cada rodada de consenso, os servidores comunicam suas propostas a outros servidores em sua Lista de Nós Únicos (UNL). Os servidores então calculam quais transações aparecem em uma porcentagem limite de propostas. Inicialmente, esse limite é definido em 50%, significando que uma transação deve aparecer em propostas de pelo menos metade da UNL de um servidor para ser considerada na próxima rodada. À medida que o consenso progride através de rodadas sucessivas, esse limite aumenta incrementalmente (tipicamente para 60%, 70% e finalmente 80%).
Quando uma transação alcança o limite de supermaioria de 80% de apoio na UNL de um servidor, ela é incluída na proposta desse servidor para a rodada final de consenso. Todas as transações que alcançam esse limite em toda a rede são aplicadas ao livro-razão, que é então criptograficamente hashado e assinado. Este livro-razão recém-validado se torna o último livro-razão fechado, e o processo recomeça com o próximo conjunto de transações candidatas.
O processo de consenso tipicamente se completa em 5 segundos ou menos, com a maioria das transações exigindo apenas uma rodada de consenso para alcançar o limite de supermaioria. As transações que não alcançam consenso em uma rodada permanecem como candidatas para rodadas subsequentes. Este design garante que a rede progrida continuamente enquanto mantém fortes garantias de segurança, já que nenhuma transação pode ser aplicada ao livro-razão sem o apoio de supermaioria dos validadores confiáveis.
Formal Analysis of Convergence
RPCA的正确性关键取决于网络中不同节点选择的UNL之间的重叠。令UNL_i表示节点i的唯一节点列表,UNL_i ∩ UNL_j表示同时出现在UNL_i和UNL_j中的节点集合。为使网络维持共识,我们要求对于任意两个节点i和j,其UNL的交集相对于任一UNL的最大规模必须足够大。
具体而言,当对所有节点对i和j满足|UNL_i ∩ UNL_j| / max(|UNL_i|, |UNL_j|) 1/5时,协议保证安全性。该条件确保即使Byzantine节点试图使网络的不同部分达成不同的共识决定,受信任节点的重叠也能防止分叉。如果该条件成立且任何UNL中Byzantine节点少于1/5,则所有正确节点将达成相同的共识决定。
形式化证明通过证明如果两个节点可以达成不同的共识决定,则必定存在某笔交易T出现在一个节点的最终账本中但不在另一个节点的账本中来进行。要发生这种情况,T必须在第一个节点的UNL中获得80%的支持,但在第二个节点的UNL中获得不到80%的支持。然而,考虑到重叠要求和对Byzantine节点的约束,可以证明这种情况是不可能的:如果T在UNL_i中获得80%的支持,它必须在满足重叠条件的任何UNL_j中至少获得60%的支持,经过足够的共识轮次,这将收敛到80%或被两个节点都拒绝。
活性属性——共识最终会达成——来自于包含阈值通过共识轮次确定性地增加这一观察。即使在存在Byzantine节点和网络延迟的情况下,协议也确保由诚实节点绝对多数支持的交易最终会被包含,而缺乏此类支持的交易将被排除。共识的有限时间(通常5秒)为支付系统应用提供了实用的活性保障。
Formal Analysis of Convergence
A correção do RPCA depende criticamente da sobreposição entre as UNLs escolhidas por diferentes nós na rede. Seja UNL_i a lista de nós únicos do nó i, e seja UNL_i ∩ UNL_j o conjunto de nós que aparecem tanto em UNL_i quanto em UNL_j. Para que a rede mantenha o consenso, exigimos que para quaisquer dois nós i e j, a interseção de suas UNLs seja suficientemente grande em relação ao tamanho máximo de qualquer uma das UNLs.
Especificamente, o protocolo garante segurança quando |UNL_i ∩ UNL_j| / max(|UNL_i|, |UNL_j|) 1/5 para todos os pares de nós i e j. Esta condição garante que mesmo se os nós Byzantine tentarem fazer com que diferentes partes da rede cheguem a diferentes decisões de consenso, a sobreposição em nós confiáveis previne uma bifurcação. Se esta condição for mantida e menos de 1/5 dos nós em qualquer UNL forem Byzantine, então todos os nós corretos chegarão à mesma decisão de consenso.
A prova formal prossegue mostrando que se dois nós pudessem chegar a diferentes decisões de consenso, deve existir alguma transação T que aparece no livro-razão final de um nó mas não no do outro. Para que isso ocorra, T deve ter alcançado 80% de apoio na UNL do primeiro nó mas menos de 80% de apoio na UNL do segundo nó. No entanto, dado o requisito de sobreposição e a restrição sobre nós Byzantine, pode-se mostrar que este cenário é impossível: se T alcançar 80% de apoio em UNL_i, deve alcançar pelo menos 60% de apoio em qualquer UNL_j que satisfaça a condição de sobreposição, e com rodadas suficientes de consenso, isso convergirá para 80% ou será rejeitado por ambos os nós.
A propriedade de vivacidade -- que o consenso eventualmente será alcançado -- segue da observação de que o limite para inclusão aumenta deterministicamente ao longo das rodadas de consenso. Mesmo na presença de nós Byzantine e atrasos de rede, o protocolo garante que as transações apoiadas por uma supermaioria de nós honestos eventualmente serão incluídas, enquanto as transações que carecem de tal apoio serão excluídas. O tempo limitado para consenso (tipicamente 5 segundos) fornece garantias práticas de vivacidade adequadas para aplicações de sistemas de pagamento.
Unique Node Lists
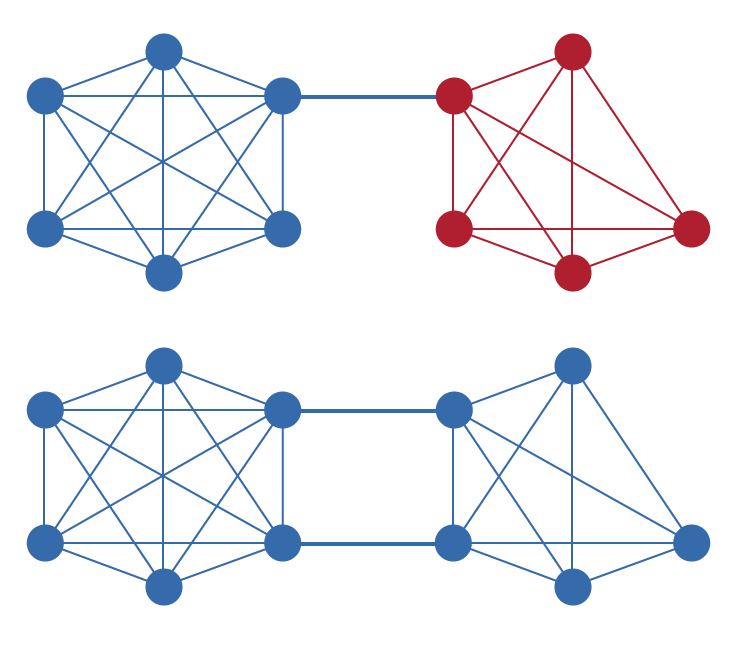
唯一节点列表(UNL)是RPCA区别于其他共识算法的基本组件。Ripple网络中的每个节点维护一个UNL,包含它信任不会串通欺骗网络的其他节点。关键的是,这种信任是局部的而非全局的:不同的节点可以有不同的UNL,不需要全局统一的验证者集合。这种设计允许网络在保持去中心化的同时有机地扩展。
UNL作为一种无需工作量证明的Sybil攻击防御机制。在简单的投票系统中,攻击者可以创建许多假名节点以获得不成比例的影响力。通过要求每个节点明确选择它信任的其他节点,RPCA确保创建额外的身份不会带来任何优势,除非这些身份能够说服现有节点将其添加到UNL中。这将Sybil抵抗的问题从计算支出转移到了声誉和信任关系上。
为使网络正确运行,UNL必须按照形式化分析中所述选择具有足够重叠的列表。在实践中,这意味着虽然每个节点运营者在选择UNL方面拥有自主权,但必须确保其列表中包含网络其他部分也信任的验证者。Ripple提供了一个由多元化实体运营的验证者组成的默认UNL,但节点运营者可以根据自己的信任评估自由修改此列表。
UNL机制还提供了一条通向渐进式去中心化的自然路径。在网络的早期阶段,更集中的验证者集合可能更适合确保稳定性和可靠性。随着网络的成熟和更多多元化运营者证明其可信度,UNL可以演变为包含更广泛的验证者集合,在不损害安全属性的情况下增强网络的韧性和去中心化程度。
Unique Node Lists
A Lista de Nós Únicos (UNL) é um componente fundamental do RPCA que o distingue de outros algoritmos de consenso. Cada nó na rede Ripple mantém uma UNL consistindo de outros nós em que confia para não conspirar para fraudar a rede. Criticamente, esta confiança é local em vez de global: diferentes nós podem ter diferentes UNLs, e não há requisito de um conjunto de validadores globalmente acordado. Este design permite que a rede escale organicamente enquanto mantém a descentralização.
A UNL serve como mecanismo de prevenção de ataques Sybil sem exigir prova de trabalho. Em um sistema de votação ingênuo, um atacante poderia criar muitos nós pseudônimos para obter influência desproporcional. Ao exigir que cada nó escolha explicitamente em quais outros nós confia, o RPCA garante que a criação de identidades adicionais não fornece nenhuma vantagem a menos que essas identidades possam convencer os nós existentes a adicioná-las às suas UNLs. Isso desloca o problema da resistência Sybil do gasto computacional para relacionamentos de reputação e confiança.
Para que a rede funcione corretamente, as UNLs devem ser escolhidas de modo que tenham sobreposição suficiente, conforme descrito na análise formal. Na prática, isso significa que embora cada operador de nó tenha autonomia na seleção de sua UNL, deve garantir que sua lista inclua validadores que também são confiados por outras partes da rede. O Ripple fornece uma UNL padrão consistindo de validadores operados por entidades diversas, mas os operadores de nós são livres para modificar esta lista com base em sua própria avaliação de confiança.
O mecanismo UNL também fornece um caminho natural em direção à descentralização progressiva. Nos estágios iniciais da rede, um conjunto mais centralizado de validadores pode ser apropriado para garantir estabilidade e confiabilidade. À medida que a rede amadurece e mais operadores diversos demonstram sua confiabilidade, as UNLs podem evoluir para incluir um conjunto mais amplo de validadores, aumentando a resiliência e descentralização da rede sem comprometer suas propriedades de segurança.
Simulation Code
为验证RPCA的理论分析并评估其在各种条件下的性能,使用定制的仿真软件进行了大量模拟。仿真框架对节点网络进行建模,每个节点维护自己的UNL并参与共识协议。代码实现了完整的RPCA算法,包括交易提案、阈值递增的投票轮次和账本验证。
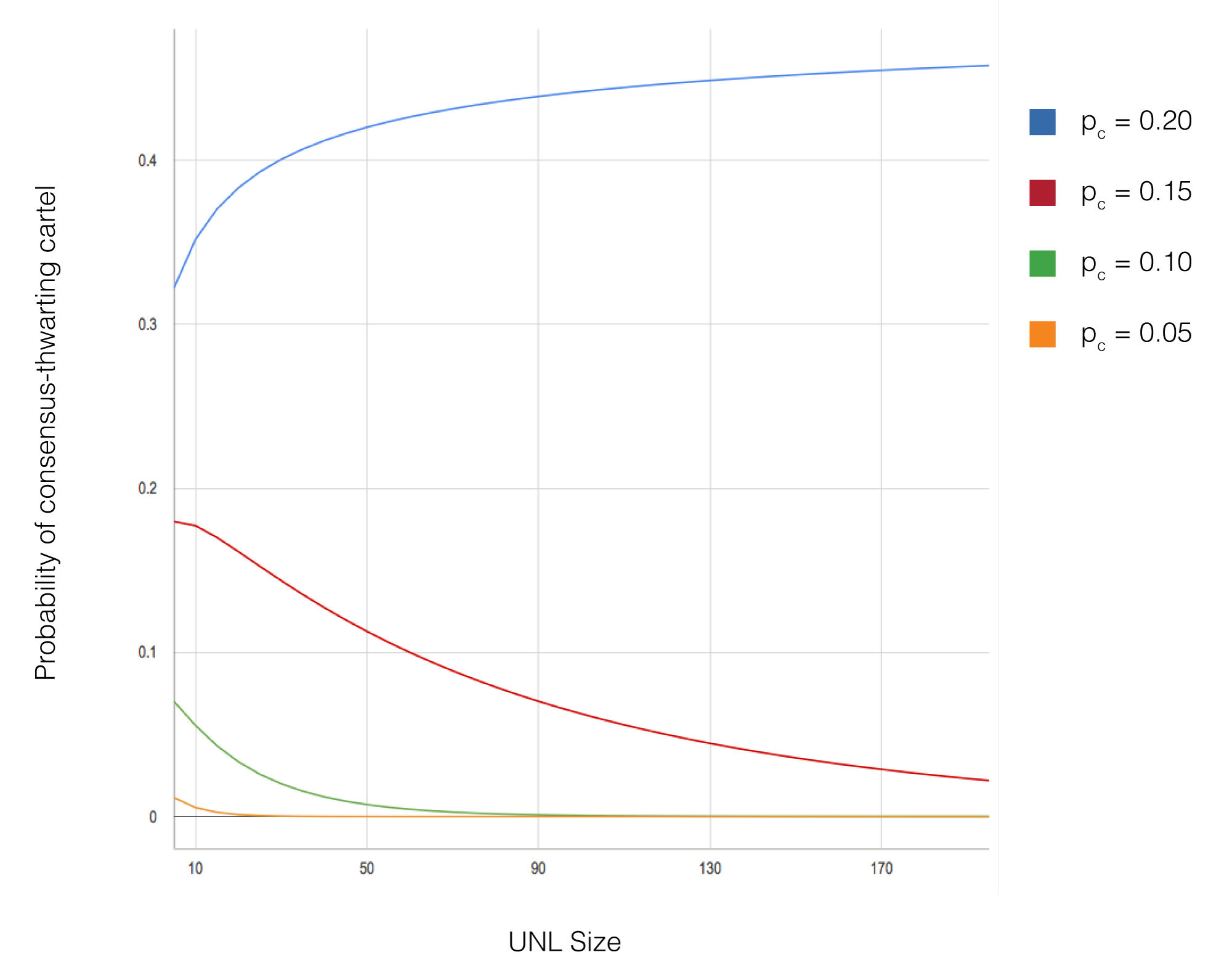
模拟中变化的关键参数包括网络规模(从10到1,000个节点)、Byzantine节点的百分比(从0%到20%)、UNL大小(通常在5到50个节点之间)和网络拓扑配置。对于每种参数配置,使用不同的随机种子进行了多次模拟运行,以确保结果的统计有效性。模拟跟踪了包括共识延迟、分叉概率和交易吞吐量在内的指标。
模拟结果证实了关于收敛和安全性的理论预测。在UNL重叠条件满足且Byzantine节点占每个UNL不到20%的所有配置中,网络成功达成共识且未出现分叉。共识延迟始终保持较低水平(通常在3-5秒的模拟时间内完成),与网络规模无关,证明了算法的可扩展性。即使有15%的Byzantine节点积极尝试破坏共识,只要满足UNL重叠要求,网络仍保持正确性。
额外的模拟探索了边缘情况和故障场景,包括网络分区、UNL组成的突然变化和Byzantine节点的协调攻击。这些模拟提供了关于协议鲁棒性的洞察,并为UNL选择和网络运营的推荐最佳实践提供了参考。完整的模拟代码已公开发布,以便进行独立验证和进一步研究。
Simulation Code
Para validar a análise teórica do RPCA e avaliar seu desempenho sob várias condições, simulações extensas foram conduzidas usando software de simulação personalizado. O framework de simulação modela uma rede de nós, cada um mantendo sua própria UNL e participando do protocolo de consenso. O código implementa o algoritmo RPCA completo, incluindo proposta de transações, rodadas de votação com limites crescentes e validação do livro-razão.
Os parâmetros-chave variados nas simulações incluem tamanho da rede (variando de 10 a 1.000 nós), a porcentagem de nós Byzantine (de 0% a 20%), tamanho da UNL (tipicamente entre 5 e 50 nós) e configurações de topologia de rede. Para cada configuração de parâmetros, múltiplas execuções de simulação foram conduzidas com diferentes sementes aleatórias para garantir a validade estatística dos resultados. As simulações rastrearam métricas incluindo latência de consenso, probabilidade de bifurcação e taxa de transferência de transações.
Os resultados da simulação confirmam as previsões teóricas sobre convergência e segurança. Em todas as configurações onde a condição de sobreposição de UNL foi satisfeita e os nós Byzantine compreendiam menos de 20% de cada UNL, a rede alcançou consenso com sucesso sem bifurcações. A latência de consenso permaneceu consistentemente baixa (tipicamente completando em 3-5 segundos simulados) independentemente do tamanho da rede, demonstrando a escalabilidade do algoritmo. Mesmo com 15% de nós Byzantine tentando ativamente interromper o consenso, a rede manteve a correção desde que o requisito de sobreposição de UNL fosse atendido.
Simulações adicionais exploraram casos extremos e cenários de falha, incluindo partições de rede, mudanças repentinas na composição da UNL e ataques coordenados por nós Byzantine. Essas simulações forneceram insights sobre a robustez do protocolo e informaram as melhores práticas recomendadas para seleção de UNL e operação de rede. O código de simulação completo foi disponibilizado para permitir verificação independente e pesquisa adicional.
Discussion
与比特币的工作量证明共识相比,RPCA为支付系统应用提供了几个显著优势。最值得注意的是,共识延迟从40-60分钟(高价值比特币交易通常建议的时间)减少到约5秒。这一改进使RPCA适用于需要近乎即时结算的销售点和其他应用。此外,RPCA与工作量证明相比所需的计算资源极少,消除了与比特币挖矿相关的大量能源消耗。
然而,这些优势伴随着不同的信任假设。比特币的安全性仅依赖于没有攻击者控制网络计算能力50%以上的假设,而RPCA要求节点选择具有足够重叠的UNL,并且Byzantine节点不超过这些UNL内的阈值。这将部分做出审慎信任决策的责任转移给了节点运营者。在实践中,对于参与机构拥有现有信任关系的许多支付系统用例,这种权衡是可以接受的。
网络拓扑和UNL选择策略显著影响共识系统的属性。所有节点在UNL中包含相同验证者的高度集中化拓扑最大化了安全性,但如果这些验证者不可用,可能会降低活性。相反,UNL重叠最小的高度去中心化拓扑可能改善活性,但如果重叠变得过于稀疏,则存在共识失败的风险。找到最佳平衡需要仔细考虑特定的部署场景和风险承受能力。
未来的研究可以探索在最大化去中心化的同时自动维护重叠要求的自适应UNL选择算法、节点根据观察到的验证者行为动态调整UNL的机制,以及可以容忍更高比例Byzantine节点的共识算法扩展。这些增强可以进一步提高RPCA在大规模分布式支付系统中的鲁棒性和适用性。
Discussion
Comparado ao consenso por prova de trabalho do Bitcoin, o RPCA oferece várias vantagens significativas para aplicações de sistemas de pagamento. Mais notavelmente, a latência de consenso é reduzida de 40-60 minutos (o tempo tipicamente recomendado para transações Bitcoin de alto valor) para aproximadamente 5 segundos. Esta melhoria torna o RPCA adequado para ponto de venda e outras aplicações onde a liquidação quase instantânea é necessária. Além disso, o RPCA requer recursos computacionais mínimos em comparação com a prova de trabalho, eliminando o consumo massivo de energia associado à mineração de Bitcoin.
No entanto, essas vantagens vêm com diferentes suposições de confiança. Enquanto a segurança do Bitcoin depende apenas da suposição de que nenhum atacante controla mais de 50% do poder computacional da rede, o RPCA exige que os nós escolham UNLs com sobreposição suficiente e que os nós Byzantine não excedam o limite dentro dessas UNLs. Isso transfere alguma responsabilidade para os operadores de nós para tomar decisões de confiança prudentes. Na prática, essa compensação é aceitável para muitos casos de uso de sistemas de pagamento onde as instituições participantes têm relacionamentos de confiança existentes.
A topologia de rede e a estratégia de seleção de UNL impactam significativamente as propriedades do sistema de consenso. Uma topologia altamente centralizada onde todos os nós incluem os mesmos validadores em suas UNLs maximiza a segurança, mas pode reduzir a vivacidade se esses validadores ficarem indisponíveis. Por outro lado, uma topologia altamente descentralizada com sobreposição mínima de UNL pode melhorar a vivacidade, mas poderia arriscar falhas de consenso se a sobreposição se tornar muito esparsa. Encontrar o equilíbrio ideal requer consideração cuidadosa do cenário de implantação específico e da tolerância ao risco.
Trabalhos futuros poderiam explorar algoritmos adaptativos de seleção de UNL que mantenham automaticamente os requisitos de sobreposição enquanto maximizam a descentralização, mecanismos para que os nós ajustem dinamicamente suas UNLs com base no comportamento observado dos validadores, e extensões ao algoritmo de consenso que possam tolerar porcentagens ainda mais altas de nós Byzantine. Essas melhorias poderiam aumentar ainda mais a robustez e aplicabilidade do RPCA para sistemas de pagamento distribuídos em larga escala.
Conclusion
Ripple协议共识算法代表了支付系统分布式共识的重要进步。通过利用集体信任的子网络而非要求所有节点之间的全局一致,RPCA在维持对Byzantine故障的强大保障的同时,在几秒内达成共识。形式化分析表明,只要UNL以足够的重叠选择且Byzantine节点保持在阈值以下,网络将达成正确的共识而不会出现分叉。
本研究的实际意义超越了Ripple支付网络。RPCA表明,共识延迟与安全保障之间的传统权衡可以通过精心的协议设计和局部信任关系的使用来克服。这种方法可能适用于其他低延迟至关重要且参与者拥有现有信任关系的分布式系统,如银行间结算系统、供应链跟踪以及其他金融基础设施应用。
RPCA在生产系统中的部署验证了算法的性能特征和鲁棒性。Ripple网络以一致的3-5秒共识延迟处理每秒数千笔交易,证明了理论属性有效地转化为实际运营。随着网络继续演进并纳入来自多元化运营者的额外验证者,它提供了一个去中心化共识系统如何在规模上同时维持安全性和性能的实际案例。
Conclusion
O Algoritmo de Consenso do Protocolo Ripple representa um avanço significativo no consenso distribuído para sistemas de pagamento. Ao utilizar sub-redes coletivamente confiáveis em vez de exigir acordo global entre todos os nós, o RPCA alcança consenso em questão de segundos enquanto mantém fortes garantias contra falhas Byzantine. A análise formal demonstra que desde que as UNLs sejam escolhidas com sobreposição suficiente e os nós Byzantine permaneçam abaixo do limite, a rede alcançará consenso correto sem bifurcações.
As implicações práticas deste trabalho se estendem além da rede de pagamentos Ripple. O RPCA demonstra que a compensação tradicional entre latência de consenso e garantias de segurança pode ser superada através de design cuidadoso do protocolo e do uso de relacionamentos de confiança locais. Esta abordagem pode se mostrar aplicável a outros sistemas distribuídos onde a baixa latência é crítica e os participantes têm relacionamentos de confiança existentes, como sistemas de liquidação interbancária, rastreamento de cadeia de suprimentos e outras aplicações de infraestrutura financeira.
A implantação do RPCA em sistemas de produção validou as características de desempenho e robustez do algoritmo. A rede Ripple processa milhares de transações por segundo com latência de consenso consistente de 3-5 segundos, demonstrando que as propriedades teóricas se traduzem efetivamente para a operação no mundo real. À medida que a rede continua a evoluir e incorporar validadores adicionais de operadores diversos, ela fornece um exemplo prático de como um sistema de consenso descentralizado pode manter tanto a segurança quanto o desempenho em escala.
References
Lamport, L., Shostak, R., and Pease, M. (1982). "The Byzantine Generals Problem." ACM Transactions on Programming Languages and Systems, 4(3):382-401. 这篇开创性论文形式化了在具有故障组件的分布式系统中达成共识的问题,并建立了Byzantine fault-tolerant系统的理论基础。
Castro, M., and Liskov, B. (1999). "Practical Byzantine Fault Tolerance." Proceedings of the Third Symposium on Operating Systems Design and Implementation (OSDI). 该研究引入了PBFT,表明Byzantine fault tolerance可以以实用的性能实现,尽管O(n^2)的通信复杂度限制了可扩展性。
Nakamoto, S. (2008). "Bitcoin: A Peer-to-Peer Electronic Cash System." 该白皮书引入了工作量证明共识作为数字货币中双重支付问题的解决方案,以高延迟和能源消耗为代价实现了无需可信方的去中心化共识。
Lamport, L. (1998). "The Part-Time Parliament." ACM Transactions on Computer Systems, 16(2):133-169. 该论文提出了Paxos算法,在崩溃故障下的异步系统中达成共识,影响了后续共识协议的设计。
Fischer, M. J., Lynch, N. A., and Paterson, M. S. (1985). "Impossibility of Distributed Consensus with One Faulty Process." Journal of the ACM, 32(2):374-382. FLP不可能性结果确立了异步系统中共识算法所能达到的基本限制,塑造了实用共识协议的设计空间。
References
Lamport, L., Shostak, R., and Pease, M. (1982). "The Byzantine Generals Problem." ACM Transactions on Programming Languages and Systems, 4(3):382-401. Este artigo seminal formalizou o problema de alcançar consenso em sistemas distribuídos com componentes defeituosos e estabeleceu a base teórica para sistemas Byzantine fault-tolerant.
Castro, M., and Liskov, B. (1999). "Practical Byzantine Fault Tolerance." Proceedings of the Third Symposium on Operating Systems Design and Implementation (OSDI). Este trabalho introduziu o PBFT, demonstrando que a Byzantine fault tolerance poderia ser alcançada com desempenho prático, embora com complexidade de comunicação O(n^2) limitando a escalabilidade.
Nakamoto, S. (2008). "Bitcoin: A Peer-to-Peer Electronic Cash System." Este whitepaper introduziu o consenso por prova de trabalho como solução para o problema do gasto duplo em moeda digital, permitindo consenso descentralizado sem partes confiáveis ao custo de alta latência e consumo de energia.
Lamport, L. (1998). "The Part-Time Parliament." ACM Transactions on Computer Systems, 16(2):133-169. Este artigo apresentou o algoritmo Paxos, que alcança consenso em sistemas assíncronos sob falhas por crash, influenciando designs subsequentes de protocolos de consenso.
Fischer, M. J., Lynch, N. A., and Paterson, M. S. (1985). "Impossibility of Distributed Consensus with One Faulty Process." Journal of the ACM, 32(2):374-382. O resultado de impossibilidade FLP estabeleceu limites fundamentais sobre o que os algoritmos de consenso podem alcançar em sistemas assíncronos, moldando o espaço de design para protocolos de consenso práticos.




