
Алгоритм консенсуса протокола Ripple
Abstract
Byzantine Generals Problemに対するいくつかの合意アルゴリズムが存在するが、特に分散型決済システムに関連して、その多くはネットワーク内のすべてのノードが同期的に通信する必要があるという要件に起因する高い遅延の問題を抱えている。本研究では、より大きなネットワーク内で集合的に信頼されたサブネットワークを活用することにより、この要件を回避する新しい合意アルゴリズムを提示する。Sybil攻撃を防止するために必要な「信頼」は、実際にはグローバルなものではなく、ネットワーク内の各ノードに対してローカルであることを示す。
Rippleプロトコル合意アルゴリズム(RPCA)は、ネットワークの正確性と合意を維持するために、すべてのノードによって数秒ごとに適用される。合意に達すると、現在の台帳は「閉鎖」されたとみなされ、最後に閉鎖された台帳(last-closed ledger)となる。このアルゴリズムは、Byzantine障害に対する強力な保証を維持しながら低い遅延で合意を達成するという点で独自であり、リアルタイムの金融決済システムに適している。
Abstract
Хотя существует несколько алгоритмов консенсуса для задачи Византийских генералов, в частности применительно к распределенным платежным системам, многие из них страдают от высокой задержки, вызванной необходимостью синхронного взаимодействия всех узлов сети. В данной работе мы представляем новый алгоритм консенсуса, который обходит это требование, используя коллективно доверенные подсети внутри более крупной сети. Мы показываем, что "доверие", необходимое для предотвращения атак Сивиллы (Sybil), на самом деле не является глобальным, а локальным для каждого узла сети.
Алгоритм консенсуса протокола Ripple (RPCA) применяется каждые несколько секунд всеми узлами для поддержания корректности и согласованности сети. После достижения консенсуса текущий леджер считается "закрытым" и становится последним закрытым леджером. Этот алгоритм уникален тем, что достигает консенсуса с низкой задержкой, сохраняя при этом надежные гарантии против византийских отказов, что делает его пригодным для систем финансовых расчетов в реальном времени.
Introduction
分散型決済システムは、障害のあるまたは悪意のあるアクターが存在する状況でも、適時に正しく決済を処理するために合意アルゴリズムを実装しなければならない。ビットコインはプルーフ・オブ・ワーク(proof-of-work)を使用して合意を達成しており、これはすべてのノードが暗号パズルを解くために計算リソースを消費することを要求する。このアプローチは強力なセキュリティ保証を提供するが、高いエネルギー消費、低いトランザクションスループット、高額取引では1時間以上に及ぶ可能性がある長い確認遅延など、重大な欠点がある。
Rippleプロトコル合意アルゴリズムは、プルーフ・オブ・ワークを必要としない分散型合意への新しいアプローチを提供する。代わりに、ネットワーク内のノードは数秒で合意を達成する投票プロセスを通じて、トランザクションセットに集合的に同意する。この合意メカニズムは、実用的な展開に低い遅延と高いスループットが不可欠なグローバル決済ネットワークの要件に合わせて特別に設計されている。
RPCAの重要なイノベーションは、ネットワーク内のすべてのノードが互いに同意する必要がないという点である。代わりに、各ノードは共謀しないと信頼する他のノードのUnique Node List(UNL)を維持する。ノードが選択したUNLが十分な重複を持ち、閾値パーセンテージ未満のノードのみが障害を持つ場合、ネットワークは合意に達する。このアプローチは、合意遅延を分や時間ではなく秒単位で測定しながら、決済システムに必要なセキュリティ保証を提供する。
Introduction
Распределенная платежная система должна реализовывать алгоритм консенсуса для корректной и своевременной обработки платежей даже при наличии неисправных или злонамеренных участников. Bitcoin достигает консенсуса с помощью доказательства работы (proof-of-work), которое требует от всех узлов затрачивать вычислительные ресурсы на решение криптографических задач. Хотя этот подход обеспечивает надежные гарантии безопасности, он имеет существенные недостатки, включая высокое энергопотребление, низкую пропускную способность транзакций и длительные задержки подтверждения, которые могут достигать часа и более для транзакций высокой стоимости.
Алгоритм консенсуса протокола Ripple предлагает новый подход к распределенному консенсусу, не требующий доказательства работы. Вместо этого узлы сети коллективно согласовывают наборы транзакций посредством процесса голосования, который достигает консенсуса за считанные секунды. Этот механизм консенсуса разработан специально для требований глобальной платежной сети, где низкая задержка и высокая пропускная способность необходимы для практического развертывания.
Ключевое нововведение RPCA заключается в том, что он не требует согласия всех узлов сети друг с другом. Вместо этого каждый узел ведет Уникальный список узлов (Unique Node List, UNL) других узлов, которым он доверяет в том, что они не вступят в сговор. Пока выбранные узлами UNL имеют достаточное пересечение и менее порогового процента узлов являются неисправными, сеть достигнет консенсуса. Этот подход обеспечивает гарантии безопасности, необходимые для платежной системы, при этом достигая задержки консенсуса, измеряемой в секундах, а не в минутах или часах.
Definition of Consensus
分散システムにおいて、合意とは、障害のあるまたは悪意のある参加者が存在する状況でも、ノードのネットワークが共有状態について合意に達するプロセスを指す。合意アルゴリズムは3つの基本的な性質を満たさなければならない:正確性(2つの正しいノードが異なる決定をしない)、合意(すべての正しいノードが同じ決定に達する)、そして終了(すべての正しいノードが最終的に決定を下す)。これらの性質は、分散システムが単一の信頼できるノードであるかのように動作することを保証する。
合意を達成する上での課題は、分散システムの本質的な不安定性に起因する。ノードがクラッシュする可能性があり、メッセージが遅延または喪失する可能性があり、Byzantineノードは任意にまたは悪意を持って振る舞う可能性がある。Lamport、Shostak、Peaseが定式化したByzantine Generals Problemは、この課題を捉えている:一部が障害を持つ可能性があり、通信が不安定な状況で、プロセスのグループはどのように合意に達することができるのか?
分散コンピューティングの古典的な結果は、合意アルゴリズムが達成できることの根本的な限界を確立している。FLP不可能性結果は、たった1つのノードが障害を起こす可能性がある非同期システムにおいて、いかなる決定論的アルゴリズムも合意を保証できないことを示している。したがって、実用的な合意アルゴリズムは、安全性(誤った合意に決して達しない)と活性(常に進行する)の間でトレードオフを行わなければならない。ビットコインのプルーフ・オブ・ワークは活性よりも安全性を優先するが、RPCAは現実的な障害仮定の下で強力な安全性保証を維持しながら、限られた時間内に合意ラウンドを完了することで、決済システムにより適したバランスを達成している。
Definition of Consensus
В распределенных системах консенсус означает процесс, посредством которого сеть узлов приходит к согласию относительно общего состояния, несмотря на наличие неисправных или злонамеренных участников. Алгоритм консенсуса должен удовлетворять трем фундаментальным свойствам: корректность (никакие два правильных узла не принимают разных решений), согласие (все правильные узлы приходят к одному решению) и завершение (все правильные узлы в конечном итоге принимают решение). Эти свойства обеспечивают поведение распределенной системы так, как если бы она была единым надежным узлом.
Сложность достижения консенсуса обусловлена присущей ненадежностью распределенных систем. Узлы могут выходить из строя, сообщения могут задерживаться или теряться, а византийские узлы могут вести себя произвольно или злонамеренно. Задача Византийских генералов, формализованная Лэмпортом, Шостаком и Пизом, отражает эту проблему: как группа процессов может достичь согласия, когда некоторая доля может быть неисправной, а связь ненадежна?
Классические результаты в области распределенных вычислений устанавливают фундаментальные пределы того, чего могут достичь алгоритмы консенсуса. Результат невозможности FLP показывает, что ни один детерминированный алгоритм не может гарантировать консенсус в асинхронной системе, если хотя бы один узел может отказать. Поэтому практические алгоритмы консенсуса должны идти на компромисс между безопасностью (никогда не достигать неверного консенсуса) и живучестью (всегда продвигаться вперед). Proof-of-work Bitcoin отдает приоритет безопасности над живучестью, тогда как RPCA достигает баланса, более подходящего для платежных систем, завершая раунды консенсуса за ограниченное время при сохранении надежных гарантий безопасности в рамках реалистичных предположений о сбоях.
Existing Consensus Algorithms
分散システムにおけるByzantine Generals Problemを解決するために、いくつかの合意アルゴリズムが提案されている。CastroとLiskovが導入したPractical Byzantine Fault Tolerance(PBFT)アルゴリズムは、3f+1個のノードからなるシステムにおいて最大f個のByzantine障害を許容できる。PBFTはすべてのノード間での複数ラウンドのメッセージ交換を通じて合意を達成し、通信計算量はO(n^2)である(nはノード数)。PBFTは強力な安全性保証と小規模ネットワークでの比較的低い遅延を提供するが、二次的な通信オーバーヘッドのため大規模ネットワークへの拡張性に課題がある。
Lamportが開発したPaxosとその変種は、非同期システムにおいて合意を提供するが、Byzantine障害ではなくクラッシュ障害を仮定している。Paxosは、提案者が値を提案し受諾者が投票する一連のラウンドを通じて合意を達成する。Paxosは任意のメッセージ遅延とプロセスクラッシュを許容できるが、Byzantine障害を処理するには慎重なエンジニアリングが必要であり、特定のシナリオではライブロック(livelock)が発生する可能性がある。
ビットコインのプルーフ・オブ・ワーク合意アルゴリズムは、Byzantine攻撃を経済的に不可能にするという根本的に異なるアプローチを取っている。ノードは暗号パズルを解くために競争し、勝者が次のトランザクションブロックを提案する。このアプローチは任意のネットワークサイズに拡張でき、Byzantine障害を処理するが、深刻な欠点がある:膨大なエネルギー消費(ビットコインネットワークで年間1億5千万ドル以上と推定)、長い確認遅延(高額取引では40〜60分であることが多い)、そして限られたスループット(毎秒約7トランザクション)。これらの制限により、プルーフ・オブ・ワークは迅速な決済と高いトランザクション量を必要とする多くの決済システムアプリケーションには不適切である。
Existing Consensus Algorithms
Для решения задачи Византийских генералов в распределенных системах было предложено несколько алгоритмов консенсуса. Алгоритм Practical Byzantine Fault Tolerance (PBFT), представленный Кастро и Лисков, может допускать до f византийских сбоев в системе из 3f+1 узлов. PBFT достигает консенсуса через несколько раундов обмена сообщениями между всеми узлами со сложностью коммуникации O(n^2), где n -- количество узлов. Хотя PBFT обеспечивает надежные гарантии безопасности и относительно низкую задержку для небольших сетей, он плохо масштабируется для больших сетей из-за квадратичных накладных расходов на коммуникацию.
Paxos и его варианты, разработанные Лэмпортом, обеспечивают консенсус в асинхронных системах, но предполагают отказы по сбою, а не византийские отказы. Paxos достигает консенсуса через серию раундов, в которых предлагающие узлы выдвигают значения, а принимающие узлы голосуют за них. Хотя Paxos может допускать произвольные задержки сообщений и отказы процессов, он требует тщательной инженерии для обработки византийских отказов и может страдать от livelock в определенных сценариях.
Алгоритм консенсуса proof-of-work Bitcoin использует принципиально иной подход, делая византийские атаки экономически нецелесообразными. Узлы соревнуются в решении криптографических задач, при этом победитель предлагает следующий блок транзакций. Хотя этот подход масштабируется до произвольных размеров сети и справляется с византийскими отказами, он имеет серьезные недостатки: огромное потребление энергии (оценивается более чем в 150 миллионов долларов в год для сети Bitcoin), длительные задержки подтверждения (часто 40-60 минут для транзакций высокой стоимости) и ограниченная пропускная способность (приблизительно 7 транзакций в секунду). Эти ограничения делают proof-of-work непригодным для многих приложений платежных систем, требующих быстрого расчета и больших объемов транзакций.
Ripple Protocol Consensus Algorithm
Rippleプロトコル合意アルゴリズム(RPCA)は、各サーバーがまだ適用されていないすべての有効なトランザクションを候補トランザクションとして収集することから始まる。その後、サーバーは現在の台帳に適用するトランザクションセットについて合意に向けて反復的に作業するマルチラウンドプロトコルに従う。各ラウンドで、サーバーは次の台帳に含めるべきだと考えるトランザクションからなる提案を作成する。
各合意ラウンド中、サーバーは自身のUnique Node List(UNL)内の他のサーバーに提案を伝達する。その後、サーバーはどのトランザクションが閾値パーセンテージ以上の提案に含まれているかを計算する。初期段階ではこの閾値は50%に設定されており、トランザクションが次のラウンドで考慮されるには、サーバーのUNLの少なくとも半分の提案に含まれている必要がある。合意が連続するラウンドを経るにつれ、この閾値は段階的に引き上げられる(通常60%、70%、そして最終的に80%)。
トランザクションがサーバーのUNLにおいて80%の絶対多数支持の閾値を達成すると、そのトランザクションは最終合意ラウンドに対するサーバーの提案に含まれる。ネットワーク全体でこの閾値に達したすべてのトランザクションは台帳に適用され、台帳は暗号学的にハッシュされ署名される。この新たに検証された台帳が最後に閉鎖された台帳となり、次の候補トランザクションセットでプロセスが再び開始される。
合意プロセスは通常5秒以内に完了し、ほとんどのトランザクションは絶対多数の閾値を達成するために1回の合意ラウンドのみを必要とする。1回のラウンドで合意を達成しなかったトランザクションは、後続のラウンドの候補として残る。この設計は、信頼された検証者の絶対多数の支持なしにはいかなるトランザクションも台帳に適用できないため、強力な安全性保証を維持しながらネットワークが継続的に進行することを保証する。
Ripple Protocol Consensus Algorithm
Алгоритм консенсуса протокола Ripple (RPCA) начинается с того, что каждый сервер берет все действительные транзакции, которые он видел и которые еще не были применены, в качестве транзакций-кандидатов. Затем серверы следуют многораундовому протоколу, в котором они итеративно работают над достижением согласия относительно набора транзакций, которые должны быть применены к текущему леджеру. В каждом раунде серверы делают предложения, состоящие из транзакций, которые, по их мнению, должны быть включены в следующий леджер.
В ходе каждого раунда консенсуса серверы передают свои предложения другим серверам из своего Уникального списка узлов (Unique Node List, UNL). Затем серверы вычисляют, какие транзакции появляются в пороговом проценте предложений. Изначально этот порог установлен на уровне 50%, что означает, что транзакция должна появиться в предложениях как минимум половины UNL сервера, чтобы быть рассмотренной в следующем раунде. По мере продвижения консенсуса через последовательные раунды этот порог увеличивается поэтапно (обычно до 60%, 70% и, наконец, 80%).
Когда транзакция достигает порога квалифицированного большинства в 80% поддержки в UNL сервера, она включается в предложение этого сервера для финального раунда консенсуса. Все транзакции, достигшие этого порога по всей сети, применяются к леджеру, который затем криптографически хешируется и подписывается. Этот вновь подтвержденный леджер становится последним закрытым леджером, и процесс начинается заново с новым набором транзакций-кандидатов.
Процесс консенсуса обычно завершается за 5 секунд или менее, при этом большинству транзакций требуется только один раунд консенсуса для достижения порога квалифицированного большинства. Транзакции, не достигшие консенсуса за один раунд, остаются кандидатами для последующих раундов. Такая конструкция обеспечивает непрерывный прогресс сети при сохранении надежных гарантий безопасности, поскольку ни одна транзакция не может быть применена к леджеру без поддержки квалифицированного большинства доверенных валидаторов.
Formal Analysis of Convergence
RPCAの正確性は、ネットワーク内の異なるノードが選択したUNL間の重複に決定的に依存する。UNL_iをノードiのUnique Node Listとし、UNL_i ∩ UNL_jをUNL_iとUNL_jの両方に含まれるノードの集合とする。ネットワークが合意を維持するためには、任意の2つのノードiとjに対して、それらのUNLの共通部分がいずれかのUNLの最大サイズに対して十分に大きい必要がある。
具体的には、プロトコルはすべてのノードペアiとjに対して|UNL_i ∩ UNL_j| / max(|UNL_i|, |UNL_j|) 1/5である場合に安全性を保証する。この条件は、Byzantineノードがネットワークの異なる部分に異なる合意決定をさせようとしても、信頼ノードの重複がフォークを防止することを保証する。この条件が成立し、いずれのUNLにおいてもByzantineノードが1/5未満であれば、すべての正しいノードは同じ合意決定に達する。
形式的証明は、2つのノードが異なる合意決定に達する可能性がある場合、一方のノードの最終台帳には含まれるがもう一方には含まれないトランザクションTが存在しなければならないことを示すことによって進む。これが発生するためには、Tが最初のノードのUNLで80%の支持を達成しているが、2番目のノードのUNLでは80%未満の支持しか得ていない必要がある。しかし、重複要件とByzantineノードの制約を考慮すると、このシナリオは不可能であることが示される:TがUNL_iで80%の支持を達成した場合、重複条件を満たすいかなるUNL_jでも少なくとも60%の支持を達成しなければならず、十分な合意ラウンドを経れば80%に収束するか、両方のノードによって拒否される。
活性の性質——合意が最終的に達成されること——は、包含のための閾値が合意ラウンドを通じて決定論的に増加するという観察から導かれる。Byzantineノードとネットワーク遅延が存在しても、プロトコルは誠実なノードの絶対多数が支持するトランザクションが最終的に含まれ、そのような支持を欠くトランザクションが除外されることを保証する。合意のための限られた時間(通常5秒)は、決済システムアプリケーションに適した実用的な活性保証を提供する。
Formal Analysis of Convergence
Корректность RPCA критически зависит от пересечения между UNL, выбранными различными узлами сети. Пусть UNL_i обозначает уникальный список узлов узла i, а UNL_i ∩ UNL_j представляет множество узлов, которые присутствуют как в UNL_i, так и в UNL_j. Для того чтобы сеть поддерживала консенсус, мы требуем, чтобы для любых двух узлов i и j пересечение их UNL было достаточно большим относительно максимального размера любого из UNL.
В частности, протокол гарантирует безопасность, когда |UNL_i ∩ UNL_j| / max(|UNL_i|, |UNL_j|) 1/5 для всех пар узлов i и j. Это условие обеспечивает, что даже если византийские узлы попытаются привести различные части сети к различным решениям консенсуса, пересечение доверенных узлов предотвращает форк. Если это условие выполняется и менее 1/5 узлов в любом UNL являются византийскими, то все корректные узлы придут к одному и тому же решению консенсуса.
Формальное доказательство проводится путем демонстрации того, что если бы два узла могли прийти к различным решениям консенсуса, должна была бы существовать транзакция T, которая присутствует в финальном леджере одного узла, но не другого. Для этого T должна была бы получить 80% поддержки в UNL первого узла, но менее 80% поддержки в UNL второго узла. Однако, учитывая требование пересечения и ограничение на византийские узлы, можно показать, что этот сценарий невозможен: если T достигает 80% поддержки в UNL_i, она должна достичь как минимум 60% поддержки в любом UNL_j, удовлетворяющем условию пересечения, и при достаточном количестве раундов консенсуса это сойдется к 80% или будет отклонено обоими узлами.
Свойство живучести -- что консенсус в конечном итоге будет достигнут -- следует из наблюдения, что порог включения детерминированно возрастает через раунды консенсуса. Даже при наличии византийских узлов и сетевых задержек протокол обеспечивает, что транзакции, поддержанные квалифицированным большинством честных узлов, в конечном итоге будут включены, тогда как транзакции без такой поддержки будут исключены. Ограниченное время для консенсуса (обычно 5 секунд) обеспечивает практические гарантии живучести, подходящие для приложений платежных систем.
Unique Node Lists
Unique Node List(UNL)は、RPCAを他の合意アルゴリズムと区別する根本的な構成要素である。Rippleネットワークの各ノードは、ネットワークを欺くために共謀しないと信頼する他のノードからなるUNLを維持する。重要なのは、この信頼がグローバルではなくローカルであるということである:異なるノードは異なるUNLを持つことができ、グローバルに合意された検証者セットは要求されない。この設計により、分散化を維持しながらネットワークが有機的に拡張できる。
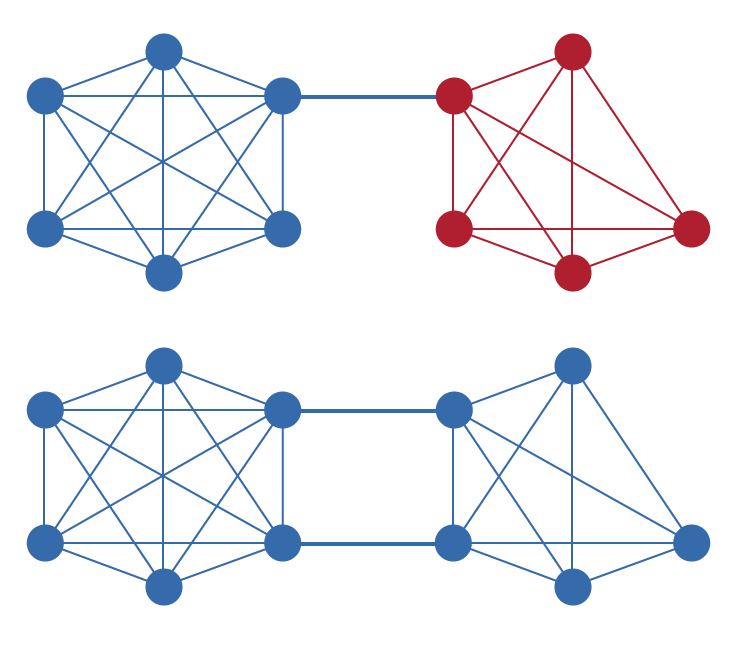
UNLは、プルーフ・オブ・ワークなしにSybil攻撃防止メカニズムとして機能する。単純な投票システムでは、攻撃者は不均衡な影響力を得るために多数の偽名ノードを作成できる。各ノードが信頼する他のノードを明示的に選択することを要求することにより、RPCAは、それらのアイデンティティが既存のノードを説得してUNLに追加されない限り、追加のアイデンティティを作成しても何の利点も得られないことを保証する。これにより、Sybil耐性の問題は計算的支出から評判と信頼関係に移行する。
ネットワークが正しく機能するためには、形式的分析で説明したように、UNLが十分な重複を持つように選択されなければならない。実際には、各ノード運営者がUNL選択において自律性を持ちながらも、ネットワークの他の部分でも信頼されている検証者をリストに含めることを保証しなければならないことを意味する。Rippleは多様なエンティティが運営する検証者からなるデフォルトUNLを提供するが、ノード運営者は独自の信頼評価に基づいてこのリストを自由に変更できる。
UNLメカニズムはまた、段階的な分散化への自然な道筋を提供する。ネットワークの初期段階では、安定性と信頼性を確保するために、より集中化された検証者セットが適切かもしれない。ネットワークが成熟し、より多様な運営者がその信頼性を実証するにつれて、UNLはセキュリティ特性を損なうことなく、ネットワークの耐障害性と分散化を高めるより広範な検証者セットを含むように進化できる。
Unique Node Lists
Уникальный список узлов (Unique Node List, UNL) является фундаментальным компонентом RPCA, который отличает его от других алгоритмов консенсуса. Каждый узел в сети Ripple ведет UNL, состоящий из других узлов, которым он доверяет в том, что они не вступят в сговор для обмана сети. Критически важно, что это доверие является локальным, а не глобальным: разные узлы могут иметь разные UNL, и нет требования глобально согласованного набора валидаторов. Такая конструкция позволяет сети масштабироваться органически при сохранении децентрализации.
UNL служит механизмом предотвращения атак Сивиллы (Sybil) без необходимости доказательства работы. В наивной системе голосования злоумышленник мог бы создать множество псевдонимных узлов для получения непропорционального влияния. Требуя от каждого узла явного выбора тех узлов, которым он доверяет, RPCA гарантирует, что создание дополнительных идентичностей не дает преимущества, если только эти идентичности не смогут убедить существующие узлы добавить их в свои UNL. Это переносит проблему устойчивости к атакам Сивиллы с вычислительных затрат на репутацию и доверительные отношения.
Для корректного функционирования сети UNL должны быть выбраны таким образом, чтобы иметь достаточное пересечение, как описано в формальном анализе. На практике это означает, что хотя каждый оператор узла имеет автономию в выборе своего UNL, он должен обеспечить, чтобы его список включал валидаторов, которым также доверяют другие части сети. Ripple предоставляет UNL по умолчанию, состоящий из валидаторов, управляемых разнообразными организациями, но операторы узлов вольны модифицировать этот список на основе собственной оценки доверия.
Механизм UNL также обеспечивает естественный путь к прогрессивной децентрализации. На ранних этапах сети более централизованный набор валидаторов может быть уместен для обеспечения стабильности и надежности. По мере созревания сети и демонстрации своей надежности разнообразными операторами UNL могут эволюционировать, включая более широкий набор валидаторов, увеличивая устойчивость и децентрализацию сети без ущерба для ее свойств безопасности.
Simulation Code
RPCAの理論的分析を検証し、さまざまな条件下でのパフォーマンスを評価するために、カスタムビルドのシミュレーションソフトウェアを使用して大規模なシミュレーションが実施された。シミュレーションフレームワークは、それぞれ独自のUNLを維持し合意プロトコルに参加するノードのネットワークをモデル化する。コードは、トランザクション提案、閾値が増加する投票ラウンド、台帳検証を含む完全なRPCAアルゴリズムを実装している。
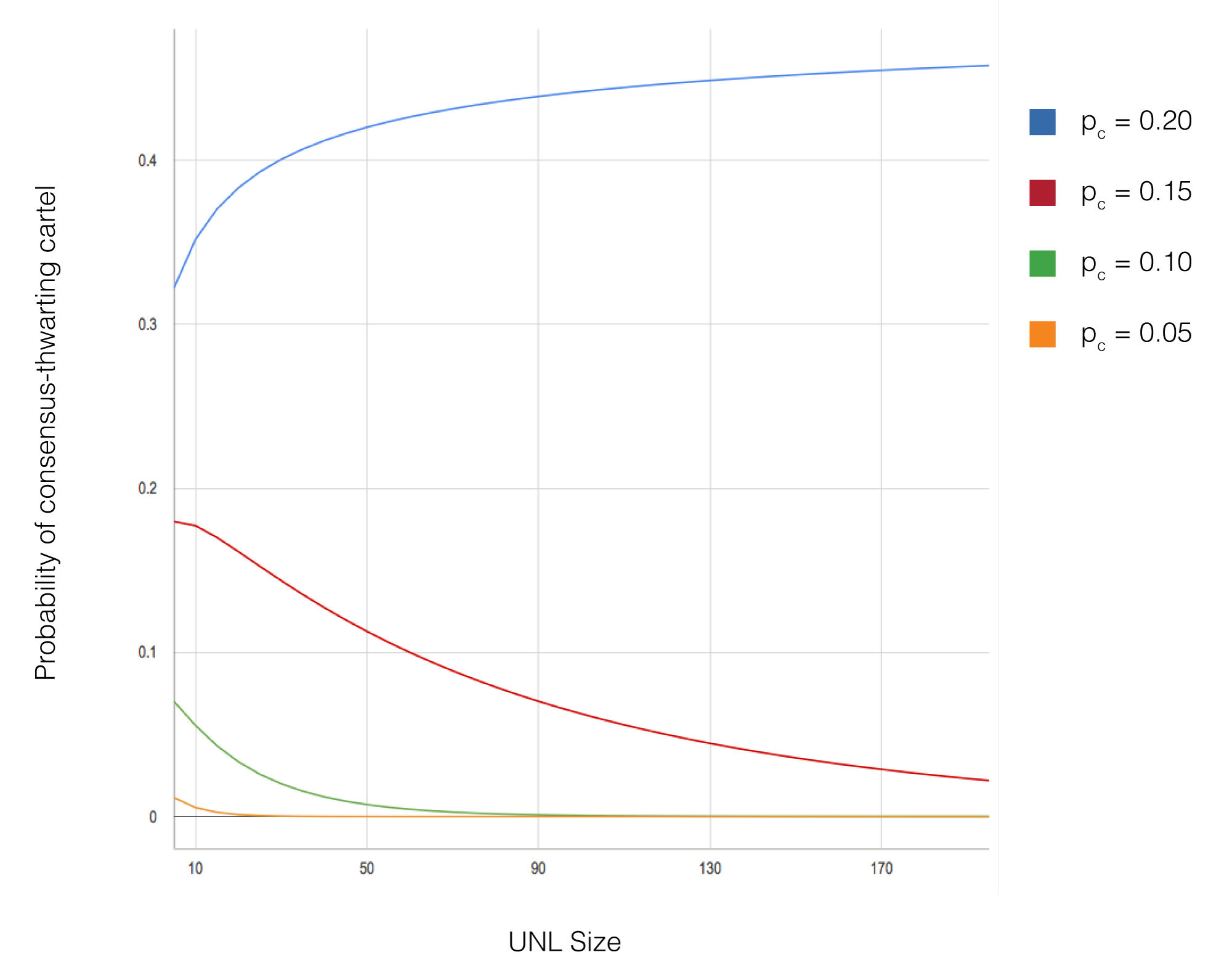
シミュレーションで変更された主要なパラメータには、ネットワークサイズ(10から1,000ノード)、Byzantineノードの割合(0%から20%)、UNLサイズ(通常5から50ノード)、およびネットワークトポロジー構成が含まれる。各パラメータ構成に対して、結果の統計的妥当性を確保するために異なるランダムシードを使用して複数のシミュレーション実行が行われた。シミュレーションは合意遅延、フォーク確率、トランザクションスループットを含むメトリクスを追跡した。
シミュレーション結果は、収束と安全性に関する理論的予測を確認している。UNL重複条件が満たされ、Byzantineノードが各UNLの20%未満であるすべての構成において、ネットワークはフォークなしに正常に合意に達した。合意遅延はネットワークサイズに関係なく一貫して低く維持され(通常3〜5秒のシミュレーション時間内に完了)、アルゴリズムのスケーラビリティを実証した。合意を妨害しようと積極的に試みる15%のByzantineノードが存在しても、UNL重複要件が満たされている限り、ネットワークは正確性を維持した。
追加のシミュレーションは、ネットワーク分割、UNL構成の突然の変更、Byzantineノードによる協調攻撃を含むエッジケースと障害シナリオを探索した。これらのシミュレーションはプロトコルの堅牢性に関する洞察を提供し、UNL選択とネットワーク運用に関する推奨ベストプラクティスの策定に寄与した。独立した検証とさらなる研究を可能にするため、完全なシミュレーションコードが公開されている。
Simulation Code
Для валидации теоретического анализа RPCA и оценки его производительности в различных условиях были проведены обширные симуляции с использованием специально разработанного программного обеспечения для моделирования. Среда моделирования представляет сеть узлов, каждый из которых ведет собственный UNL и участвует в протоколе консенсуса. Код реализует полный алгоритм RPCA, включая предложение транзакций, раунды голосования с возрастающими порогами и валидацию леджера.
Ключевые параметры, варьировавшиеся в симуляциях, включают размер сети (от 10 до 1 000 узлов), процент византийских узлов (от 0% до 20%), размер UNL (обычно от 5 до 50 узлов) и конфигурации топологии сети. Для каждой конфигурации параметров было проведено несколько запусков симуляции с различными случайными начальными значениями для обеспечения статистической достоверности результатов. В симуляциях отслеживались такие метрики, как задержка консенсуса, вероятность форка и пропускная способность транзакций.
Результаты моделирования подтверждают теоретические предсказания относительно сходимости и безопасности. Во всех конфигурациях, где условие пересечения UNL было выполнено и византийские узлы составляли менее 20% каждого UNL, сеть успешно достигала консенсуса без форков. Задержка консенсуса оставалась стабильно низкой (обычно завершаясь за 3-5 смоделированных секунд) независимо от размера сети, демонстрируя масштабируемость алгоритма. Даже при 15% византийских узлов, активно пытающихся нарушить консенсус, сеть сохраняла корректность при выполнении требования пересечения UNL.
Дополнительные симуляции исследовали граничные случаи и сценарии отказов, включая разделение сети, внезапные изменения состава UNL и координированные атаки византийских узлов. Эти симуляции предоставили информацию о надежности протокола и определили рекомендуемые лучшие практики для выбора UNL и эксплуатации сети. Полный код моделирования был предоставлен для независимой верификации и дальнейших исследований.
Discussion
ビットコインのプルーフ・オブ・ワーク合意と比較して、RPCAは決済システムアプリケーションにいくつかの重要な利点を提供する。最も注目すべきは、合意遅延が40〜60分(高額ビットコイン取引に通常推奨される時間)から約5秒に短縮されることである。この改善により、RPCAはほぼ即時の決済が必要なPOS(販売時点)やその他のアプリケーションに適している。さらに、RPCAはプルーフ・オブ・ワークと比較して最小限の計算リソースしか必要とせず、ビットコインマイニングに伴う膨大なエネルギー消費を排除する。
しかし、これらの利点には異なる信頼仮定が伴う。ビットコインのセキュリティが、いかなる攻撃者もネットワークの計算能力の50%以上を制御しないという仮定のみに依存するのに対し、RPCAはノードが十分な重複を持つUNLを選択し、ByzantineノードがこれらのUNL内で閾値を超えないことを要求する。これにより、慎重な信頼決定を行う責任の一部がノード運営者に移る。実際には、参加機関が既存の信頼関係を持つ多くの決済システムユースケースにおいて、このトレードオフは許容可能である。
ネットワークトポロジーとUNL選択戦略は、合意システムの特性に大きく影響する。すべてのノードがUNLに同じ検証者を含む高度に集中化されたトポロジーは安全性を最大化するが、それらの検証者が利用不可になった場合、活性が低下する可能性がある。逆に、UNLの重複が最小限の高度に分散化されたトポロジーは活性を改善する可能性があるが、重複が疎になりすぎると合意障害のリスクがある。最適なバランスを見つけるには、特定のデプロイメントシナリオとリスク許容度の慎重な考慮が必要である。
将来の研究では、分散化を最大化しながら重複要件を自動的に維持する適応的UNL選択アルゴリズム、観察された検証者の行動に基づいてノードがUNLを動的に調整するメカニズム、そしてさらに高い割合のByzantineノードを許容できる合意アルゴリズムの拡張を探求できる可能性がある。これらの強化により、大規模分散型決済システムに対するRPCAの堅牢性と適用可能性がさらに向上する可能性がある。
Discussion
По сравнению с консенсусом proof-of-work Bitcoin, RPCA предлагает несколько значительных преимуществ для приложений платежных систем. Наиболее примечательно, что задержка консенсуса сокращается с 40-60 минут (время, обычно рекомендуемое для высокостоимостных транзакций Bitcoin) до примерно 5 секунд. Это улучшение делает RPCA пригодным для точек продаж и других приложений, где требуется практически мгновенный расчет. Кроме того, RPCA требует минимальных вычислительных ресурсов по сравнению с proof-of-work, устраняя огромное потребление энергии, связанное с майнингом Bitcoin.
Однако эти преимущества сопряжены с иными предположениями о доверии. В то время как безопасность Bitcoin основывается только на предположении, что ни один злоумышленник не контролирует более 50% вычислительной мощности сети, RPCA требует, чтобы узлы выбирали UNL с достаточным пересечением и чтобы византийские узлы не превышали порог в этих UNL. Это перекладывает часть ответственности на операторов узлов за принятие разумных решений о доверии. На практике этот компромисс приемлем для многих случаев использования платежных систем, где участвующие учреждения имеют существующие доверительные отношения.
Топология сети и стратегия выбора UNL существенно влияют на свойства системы консенсуса. Высокоцентрализованная топология, при которой все узлы включают одних и тех же валидаторов в свои UNL, максимизирует безопасность, но может снизить живучесть, если эти валидаторы станут недоступными. И наоборот, высокодецентрализованная топология с минимальным пересечением UNL может улучшить живучесть, но рискует привести к сбоям консенсуса, если пересечение станет слишком малым. Нахождение оптимального баланса требует тщательного рассмотрения конкретного сценария развертывания и допустимого уровня риска.
Будущие работы могут исследовать адаптивные алгоритмы выбора UNL, которые автоматически поддерживают требования пересечения при максимизации децентрализации, механизмы для динамической корректировки UNL узлами на основе наблюдаемого поведения валидаторов и расширения алгоритма консенсуса, которые могли бы допускать еще более высокие доли византийских узлов. Эти улучшения могут дополнительно повысить надежность и применимость RPCA для крупномасштабных распределенных платежных систем.
Conclusion
Rippleプロトコル合意アルゴリズムは、決済システムのための分散型合意における重要な進歩を表している。すべてのノード間のグローバルな合意を要求する代わりに、集合的に信頼されたサブネットワークを活用することにより、RPCAはByzantine障害に対する強力な保証を維持しながら数秒で合意を達成する。形式的分析は、UNLが十分な重複で選択され、Byzantineノードが閾値以下に維持される限り、ネットワークがフォークなしに正しい合意に達することを実証している。
本研究の実用的な意味合いは、Ripple決済ネットワークを超えて広がる。RPCAは、合意遅延とセキュリティ保証の間の従来のトレードオフが、慎重なプロトコル設計とローカルな信頼関係の利用を通じて克服できることを示している。このアプローチは、低い遅延が重要であり参加者が既存の信頼関係を持つ他の分散システム、例えば銀行間決済システム、サプライチェーン追跡、その他の金融インフラアプリケーションに適用可能であると考えられる。
本番システムにおけるRPCAの展開は、アルゴリズムのパフォーマンス特性と堅牢性を検証した。Rippleネットワークは、一貫した3〜5秒の合意遅延で毎秒数千のトランザクションを処理しており、理論的特性が実世界の運用に効果的に反映されることを実証している。ネットワークが進化を続け、多様な運営者からの追加の検証者を組み込むにつれ、分散型合意システムがスケールにおいてセキュリティとパフォーマンスの両方を維持できる方法の実用的な事例を提供している。
Conclusion
Алгоритм консенсуса протокола Ripple представляет собой значительное достижение в области распределенного консенсуса для платежных систем. Используя коллективно доверенные подсети вместо требования глобального согласия между всеми узлами, RPCA достигает консенсуса за считанные секунды, сохраняя при этом надежные гарантии против византийских отказов. Формальный анализ демонстрирует, что при условии выбора UNL с достаточным пересечением и нахождении византийских узлов ниже порогового значения сеть достигнет корректного консенсуса без форков.
Практические последствия этой работы выходят за рамки платежной сети Ripple. RPCA демонстрирует, что традиционный компромисс между задержкой консенсуса и гарантиями безопасности может быть преодолен посредством тщательного проектирования протокола и использования локальных доверительных отношений. Этот подход может оказаться применимым к другим распределенным системам, где критически важна низкая задержка и участники имеют существующие доверительные отношения, таким как системы межбанковских расчетов, отслеживание цепочек поставок и другие приложения финансовой инфраструктуры.
Развертывание RPCA в производственных системах подтвердило характеристики производительности и надежность алгоритма. Сеть Ripple обрабатывает тысячи транзакций в секунду со стабильной задержкой консенсуса 3-5 секунд, демонстрируя, что теоретические свойства эффективно переносятся на реальную эксплуатацию. По мере дальнейшего развития сети и включения дополнительных валидаторов от разнообразных операторов она служит практическим примером того, как децентрализованная система консенсуса может поддерживать как безопасность, так и производительность в масштабе.
References
Lamport, L., Shostak, R., and Pease, M. (1982). "The Byzantine Generals Problem." ACM Transactions on Programming Languages and Systems, 4(3):382-401. この画期的な論文は、障害のあるコンポーネントを持つ分散システムにおいて合意に達する問題を定式化し、Byzantine fault-tolerantシステムの理論的基盤を確立した。
Castro, M., and Liskov, B. (1999). "Practical Byzantine Fault Tolerance." Proceedings of the Third Symposium on Operating Systems Design and Implementation (OSDI). この研究はPBFTを導入し、Byzantine fault toleranceが実用的なパフォーマンスで達成できることを実証したが、O(n^2)の通信計算量がスケーラビリティを制限した。
Nakamoto, S. (2008). "Bitcoin: A Peer-to-Peer Electronic Cash System." このホワイトペーパーは、デジタル通貨における二重支出問題の解決策としてプルーフ・オブ・ワーク合意を導入し、高い遅延とエネルギー消費を代償として、信頼できる当事者なしに分散型合意を可能にした。
Lamport, L. (1998). "The Part-Time Parliament." ACM Transactions on Computer Systems, 16(2):133-169. この論文は、クラッシュ障害の下で非同期システムにおいて合意を達成するPaxosアルゴリズムを提示し、その後の合意プロトコル設計に影響を与えた。
Fischer, M. J., Lynch, N. A., and Paterson, M. S. (1985). "Impossibility of Distributed Consensus with One Faulty Process." Journal of the ACM, 32(2):374-382. FLP不可能性結果は、非同期システムにおいて合意アルゴリズムが達成できることの根本的な限界を確立し、実用的な合意プロトコルの設計空間を形成した。
References
Lamport, L., Shostak, R., and Pease, M. (1982). "The Byzantine Generals Problem." ACM Transactions on Programming Languages and Systems, 4(3):382-401. Эта основополагающая статья формализовала проблему достижения консенсуса в распределенных системах с неисправными компонентами и заложила теоретическую основу для византийски отказоустойчивых систем.
Castro, M., and Liskov, B. (1999). "Practical Byzantine Fault Tolerance." Proceedings of the Third Symposium on Operating Systems Design and Implementation (OSDI). Эта работа представила PBFT, продемонстрировав, что византийская отказоустойчивость может быть достигнута с практической производительностью, хотя со сложностью коммуникации O(n^2), ограничивающей масштабируемость.
Nakamoto, S. (2008). "Bitcoin: A Peer-to-Peer Electronic Cash System." Эта белая книга представила консенсус на основе доказательства работы как решение проблемы двойного расходования в цифровой валюте, обеспечив децентрализованный консенсус без доверенных сторон ценой высокой задержки и потребления энергии.
Lamport, L. (1998). "The Part-Time Parliament." ACM Transactions on Computer Systems, 16(2):133-169. Эта статья представила алгоритм Paxos, который достигает консенсуса в асинхронных системах при отказах по сбою, повлияв на последующие разработки протоколов консенсуса.
Fischer, M. J., Lynch, N. A., and Paterson, M. S. (1985). "Impossibility of Distributed Consensus with One Faulty Process." Journal of the ACM, 32(2):374-382. Результат невозможности FLP установил фундаментальные пределы того, чего алгоритмы консенсуса могут достичь в асинхронных системах, определив пространство проектирования для практических протоколов консенсуса.




