
อัลกอริทึมฉันทามติของโปรโตคอล Ripple
Abstract
Byzantine Generals Problemに対するいくつかの合意アルゴリズムが存在するが、特に分散型決済システムに関連して、その多くはネットワーク内のすべてのノードが同期的に通信する必要があるという要件に起因する高い遅延の問題を抱えている。本研究では、より大きなネットワーク内で集合的に信頼されたサブネットワークを活用することにより、この要件を回避する新しい合意アルゴリズムを提示する。Sybil攻撃を防止するために必要な「信頼」は、実際にはグローバルなものではなく、ネットワーク内の各ノードに対してローカルであることを示す。
Rippleプロトコル合意アルゴリズム(RPCA)は、ネットワークの正確性と合意を維持するために、すべてのノードによって数秒ごとに適用される。合意に達すると、現在の台帳は「閉鎖」されたとみなされ、最後に閉鎖された台帳(last-closed ledger)となる。このアルゴリズムは、Byzantine障害に対する強力な保証を維持しながら低い遅延で合意を達成するという点で独自であり、リアルタイムの金融決済システムに適している。
Abstract
แม้ว่าจะมีอัลกอริทึมฉันทามติหลายแบบสำหรับปัญหานายพลไบแซนไทน์ โดยเฉพาะในบริบทของระบบการชำระเงินแบบกระจาย แต่หลายแนวทางยังมีความหน่วงสูงจากข้อกำหนดที่ว่าโหนดทั้งหมดในเครือข่ายต้องสื่อสารกันแบบซิงโครนัส งานนี้นำเสนออัลกอริทึมฉันทามติแบบใหม่ที่หลีกเลี่ยงข้อกำหนดดังกล่าว โดยอาศัยเครือข่ายย่อยที่ได้รับความไว้วางใจร่วมกันภายในเครือข่ายขนาดใหญ่กว่า เราแสดงให้เห็นว่า "ความไว้วางใจ" ที่จำเป็นต่อการป้องกันการโจมตี Sybil ไม่ได้เป็นแบบทั่วโลก แต่เป็นแบบเฉพาะที่ในระดับแต่ละโหนด
Ripple Protocol Consensus Algorithm (RPCA) ถูกนำมาใช้ทุก ๆ ไม่กี่วินาทีโดยทุกโหนด เพื่อรักษาความถูกต้องและความสอดคล้องของเครือข่าย เมื่อได้ฉันทามติแล้ว ledger ปัจจุบันจะถือว่า "ปิด" และกลายเป็น last-closed ledger อัลกอริทึมนี้โดดเด่นตรงที่ให้ฉันทามติได้ด้วยความหน่วงต่ำ ขณะยังคงการรับประกันที่แข็งแรงต่อความล้มเหลวแบบ Byzantine จึงเหมาะกับระบบชำระบัญชีทางการเงินแบบเรียลไทม์
Introduction
分散型決済システムは、障害のあるまたは悪意のあるアクターが存在する状況でも、適時に正しく決済を処理するために合意アルゴリズムを実装しなければならない。ビットコインはプルーフ・オブ・ワーク(proof-of-work)を使用して合意を達成しており、これはすべてのノードが暗号パズルを解くために計算リソースを消費することを要求する。このアプローチは強力なセキュリティ保証を提供するが、高いエネルギー消費、低いトランザクションスループット、高額取引では1時間以上に及ぶ可能性がある長い確認遅延など、重大な欠点がある。
Rippleプロトコル合意アルゴリズムは、プルーフ・オブ・ワークを必要としない分散型合意への新しいアプローチを提供する。代わりに、ネットワーク内のノードは数秒で合意を達成する投票プロセスを通じて、トランザクションセットに集合的に同意する。この合意メカニズムは、実用的な展開に低い遅延と高いスループットが不可欠なグローバル決済ネットワークの要件に合わせて特別に設計されている。
RPCAの重要なイノベーションは、ネットワーク内のすべてのノードが互いに同意する必要がないという点である。代わりに、各ノードは共謀しないと信頼する他のノードのUnique Node List(UNL)を維持する。ノードが選択したUNLが十分な重複を持ち、閾値パーセンテージ未満のノードのみが障害を持つ場合、ネットワークは合意に達する。このアプローチは、合意遅延を分や時間ではなく秒単位で測定しながら、決済システムに必要なセキュリティ保証を提供する。
Introduction
ระบบการชำระเงินแบบกระจายจำเป็นต้องมีอัลกอริทึมฉันทามติเพื่อประมวลผลการชำระเงินให้ถูกต้องและทันเวลา แม้ในสภาพที่มีผู้มีส่วนร่วมที่ผิดพลาดหรือประสงค์ร้าย Bitcoin บรรลุฉันทามติด้วย proof-of-work ซึ่งกำหนดให้ทุกโหนดใช้ทรัพยากรคอมพิวเตอร์ในการแก้ปริศนาการเข้ารหัส แม้วิธีนี้จะให้การรับประกันความปลอดภัยที่แข็งแรง แต่ก็มีข้อเสียสำคัญ ได้แก่ การใช้พลังงานสูง ปริมาณธุรกรรมต่อเวลาต่ำ และความหน่วงในการยืนยันที่ยาวนาน ซึ่งอาจนานถึงหนึ่งชั่วโมงหรือมากกว่านั้นสำหรับธุรกรรมมูลค่าสูง
Ripple Protocol Consensus Algorithm เสนอแนวทางใหม่ของฉันทามติแบบกระจายที่ไม่ต้องอาศัย proof-of-work แทนที่จะทำเช่นนั้น โหนดในเครือข่ายจะร่วมกันตกลงบนชุดธุรกรรมผ่านกระบวนการโหวตที่ได้ฉันทามติภายในไม่กี่วินาที กลไกนี้ออกแบบมาโดยเฉพาะสำหรับข้อกำหนดของเครือข่ายการชำระเงินระดับโลก ซึ่งความหน่วงต่ำและปริมาณงานสูงเป็นเงื่อนไขสำคัญต่อการใช้งานจริง
นวัตกรรมหลักของ RPCA คือไม่ต้องให้ทุกโหนดในเครือข่ายเห็นพ้องกันทั้งหมด แต่ให้แต่ละโหนดเก็บ Unique Node List (UNL) ของโหนดอื่นที่ตนเชื่อว่าจะไม่สมรู้ร่วมคิด ตราบใดที่ UNL ของโหนดต่าง ๆ มีการทับซ้อนเพียงพอ และจำนวนโหนดที่ผิดพลาดต่ำกว่าเกณฑ์ที่กำหนด เครือข่ายจะบรรลุฉันทามติได้ แนวทางนี้ให้การรับประกันความปลอดภัยที่ระบบการชำระเงินต้องการ พร้อมกับความหน่วงฉันทามติระดับวินาทีแทนนาทีหรือชั่วโมง
Definition of Consensus
分散システムにおいて、合意とは、障害のあるまたは悪意のある参加者が存在する状況でも、ノードのネットワークが共有状態について合意に達するプロセスを指す。合意アルゴリズムは3つの基本的な性質を満たさなければならない:正確性(2つの正しいノードが異なる決定をしない)、合意(すべての正しいノードが同じ決定に達する)、そして終了(すべての正しいノードが最終的に決定を下す)。これらの性質は、分散システムが単一の信頼できるノードであるかのように動作することを保証する。
合意を達成する上での課題は、分散システムの本質的な不安定性に起因する。ノードがクラッシュする可能性があり、メッセージが遅延または喪失する可能性があり、Byzantineノードは任意にまたは悪意を持って振る舞う可能性がある。Lamport、Shostak、Peaseが定式化したByzantine Generals Problemは、この課題を捉えている:一部が障害を持つ可能性があり、通信が不安定な状況で、プロセスのグループはどのように合意に達することができるのか?
分散コンピューティングの古典的な結果は、合意アルゴリズムが達成できることの根本的な限界を確立している。FLP不可能性結果は、たった1つのノードが障害を起こす可能性がある非同期システムにおいて、いかなる決定論的アルゴリズムも合意を保証できないことを示している。したがって、実用的な合意アルゴリズムは、安全性(誤った合意に決して達しない)と活性(常に進行する)の間でトレードオフを行わなければならない。ビットコインのプルーフ・オブ・ワークは活性よりも安全性を優先するが、RPCAは現実的な障害仮定の下で強力な安全性保証を維持しながら、限られた時間内に合意ラウンドを完了することで、決済システムにより適したバランスを達成している。
Definition of Consensus
ในระบบแบบกระจาย ฉันทามติคือกระบวนการที่เครือข่ายของโหนดตกลงร่วมกันบนสถานะเดียวกัน แม้จะมีผู้เข้าร่วมที่ผิดพลาดหรือประสงค์ร้าย อัลกอริทึมฉันทามติต้องมีคุณสมบัติพื้นฐานสามประการ ได้แก่ correctness (โหนดที่ถูกต้องสองโหนดต้องไม่ตัดสินใจต่างกัน), agreement (โหนดที่ถูกต้องทั้งหมดต้องตัดสินใจเหมือนกัน), และ termination (โหนดที่ถูกต้องทั้งหมดต้องตัดสินใจได้ในที่สุด) คุณสมบัติเหล่านี้ทำให้ระบบกระจายทำงานเสมือนเป็นโหนดเดียวที่เชื่อถือได้
ความท้าทายของการบรรลุฉันทามติมาจากความไม่น่าเชื่อถือโดยธรรมชาติของระบบกระจาย โหนดอาจล่ม ข้อความอาจล่าช้าหรือสูญหาย และโหนด Byzantine อาจมีพฤติกรรมตามอำเภอใจหรือเป็นอันตราย ปัญหานายพลไบแซนไทน์ที่ Lamport, Shostak และ Pease นิยามไว้อย่างเป็นทางการ สะท้อนความท้าทายนี้โดยตรง: กลุ่มโปรเซสจะตกลงร่วมกันได้อย่างไรเมื่อบางส่วนอาจผิดพลาดและการสื่อสารไม่น่าเชื่อถือ
ผลลัพธ์คลาสสิกในงานคำนวณแบบกระจายชี้ให้เห็นขอบเขตพื้นฐานของสิ่งที่อัลกอริทึมฉันทามติทำได้ ผลลัพธ์ความเป็นไปไม่ได้ของ FLP แสดงว่าไม่มีอัลกอริทึมเชิงกำหนดใดรับประกันฉันทามติได้ในระบบอะซิงโครนัส หากแม้แต่โหนดเดียวมีโอกาสล้มเหลว ดังนั้นอัลกอริทึมฉันทามติภาคปฏิบัติจึงต้องแลกเปลี่ยนระหว่าง safety (ไม่บรรลุฉันทามติที่ผิด) และ liveness (ระบบยังคงเดินหน้าได้เสมอ) proof-of-work ของ Bitcoin ให้ความสำคัญกับ safety มากกว่า liveness ขณะที่ RPCA สร้างสมดุลที่เหมาะกับระบบชำระเงินมากกว่า โดยปิดรอบฉันทามติได้ภายในเวลาจำกัดและยังคงการรับประกัน safety ที่แข็งแรงภายใต้สมมติฐานความผิดพลาดที่สมจริง
Existing Consensus Algorithms
分散システムにおけるByzantine Generals Problemを解決するために、いくつかの合意アルゴリズムが提案されている。CastroとLiskovが導入したPractical Byzantine Fault Tolerance(PBFT)アルゴリズムは、3f+1個のノードからなるシステムにおいて最大f個のByzantine障害を許容できる。PBFTはすべてのノード間での複数ラウンドのメッセージ交換を通じて合意を達成し、通信計算量はO(n^2)である(nはノード数)。PBFTは強力な安全性保証と小規模ネットワークでの比較的低い遅延を提供するが、二次的な通信オーバーヘッドのため大規模ネットワークへの拡張性に課題がある。
Lamportが開発したPaxosとその変種は、非同期システムにおいて合意を提供するが、Byzantine障害ではなくクラッシュ障害を仮定している。Paxosは、提案者が値を提案し受諾者が投票する一連のラウンドを通じて合意を達成する。Paxosは任意のメッセージ遅延とプロセスクラッシュを許容できるが、Byzantine障害を処理するには慎重なエンジニアリングが必要であり、特定のシナリオではライブロック(livelock)が発生する可能性がある。
ビットコインのプルーフ・オブ・ワーク合意アルゴリズムは、Byzantine攻撃を経済的に不可能にするという根本的に異なるアプローチを取っている。ノードは暗号パズルを解くために競争し、勝者が次のトランザクションブロックを提案する。このアプローチは任意のネットワークサイズに拡張でき、Byzantine障害を処理するが、深刻な欠点がある:膨大なエネルギー消費(ビットコインネットワークで年間1億5千万ドル以上と推定)、長い確認遅延(高額取引では40〜60分であることが多い)、そして限られたスループット(毎秒約7トランザクション)。これらの制限により、プルーフ・オブ・ワークは迅速な決済と高いトランザクション量を必要とする多くの決済システムアプリケーションには不適切である。
Existing Consensus Algorithms
มีการเสนออัลกอริทึมฉันทามติหลายแบบเพื่อแก้ปัญหานายพลไบแซนไทน์ในระบบแบบกระจาย อัลกอริทึม Practical Byzantine Fault Tolerance (PBFT) ที่ Castro และ Liskov นำเสนอ สามารถทนต่อความผิดพลาดแบบ Byzantine ได้สูงสุด f ตัว ในระบบที่มี 3f+1 โหนด PBFT บรรลุฉันทามติผ่านหลายรอบของการแลกเปลี่ยนข้อความระหว่างทุกโหนด โดยมีความซับซ้อนด้านการสื่อสาร O(n^2) เมื่อ n คือจำนวนโหนด แม้ PBFT จะให้ safety ที่แข็งแรงและความหน่วงค่อนข้างต่ำในเครือข่ายขนาดเล็ก แต่ไม่ขยายตัวได้ดีในเครือข่ายขนาดใหญ่เนื่องจากภาระการสื่อสารแบบกำลังสอง
Paxos และอนุพันธ์ซึ่งพัฒนาโดย Lamport ให้ฉันทามติในระบบอะซิงโครนัส แต่ตั้งสมมติฐานความผิดพลาดแบบ crash แทน Byzantine Paxos ทำงานผ่านชุดรอบที่ proposer เสนอค่าและ acceptor โหวต แม้ Paxos จะทนต่อความล่าช้าของข้อความแบบไม่จำกัดและการล่มของโปรเซสได้ แต่การรับมือความผิดพลาดแบบ Byzantine ต้องใช้การออกแบบวิศวกรรมอย่างระมัดระวัง และในบางสถานการณ์อาจเกิด livelock
ฉันทามติแบบ proof-of-work ของ Bitcoin ใช้แนวทางที่ต่างออกไปโดยสิ้นเชิง คือทำให้การโจมตี Byzantine ไม่คุ้มค่าทางเศรษฐศาสตร์ โหนดแข่งขันกันแก้ปริศนาการเข้ารหัส โดยผู้ชนะจะเสนอ block ธุรกรรมถัดไป แม้แนวทางนี้จะสเกลได้กับขนาดเครือข่ายตามต้องการและรองรับความผิดพลาดแบบ Byzantine แต่มีข้อเสียรุนแรง ได้แก่ การใช้พลังงานมหาศาล (มีการประเมินว่าเกิน 150 ล้านดอลลาร์ต่อปีสำหรับเครือข่าย Bitcoin), ความหน่วงในการยืนยันยาวนาน (มัก 40-60 นาทีสำหรับธุรกรรมมูลค่าสูง), และ throughput ที่จำกัด (ประมาณ 7 ธุรกรรมต่อวินาที) ข้อจำกัดเหล่านี้ทำให้ proof-of-work ไม่เหมาะกับหลายกรณีใช้งานระบบชำระเงินที่ต้องการการชำระบัญชีรวดเร็วและปริมาณธุรกรรมสูง
Ripple Protocol Consensus Algorithm
Rippleプロトコル合意アルゴリズム(RPCA)は、各サーバーがまだ適用されていないすべての有効なトランザクションを候補トランザクションとして収集することから始まる。その後、サーバーは現在の台帳に適用するトランザクションセットについて合意に向けて反復的に作業するマルチラウンドプロトコルに従う。各ラウンドで、サーバーは次の台帳に含めるべきだと考えるトランザクションからなる提案を作成する。
各合意ラウンド中、サーバーは自身のUnique Node List(UNL)内の他のサーバーに提案を伝達する。その後、サーバーはどのトランザクションが閾値パーセンテージ以上の提案に含まれているかを計算する。初期段階ではこの閾値は50%に設定されており、トランザクションが次のラウンドで考慮されるには、サーバーのUNLの少なくとも半分の提案に含まれている必要がある。合意が連続するラウンドを経るにつれ、この閾値は段階的に引き上げられる(通常60%、70%、そして最終的に80%)。
トランザクションがサーバーのUNLにおいて80%の絶対多数支持の閾値を達成すると、そのトランザクションは最終合意ラウンドに対するサーバーの提案に含まれる。ネットワーク全体でこの閾値に達したすべてのトランザクションは台帳に適用され、台帳は暗号学的にハッシュされ署名される。この新たに検証された台帳が最後に閉鎖された台帳となり、次の候補トランザクションセットでプロセスが再び開始される。
合意プロセスは通常5秒以内に完了し、ほとんどのトランザクションは絶対多数の閾値を達成するために1回の合意ラウンドのみを必要とする。1回のラウンドで合意を達成しなかったトランザクションは、後続のラウンドの候補として残る。この設計は、信頼された検証者の絶対多数の支持なしにはいかなるトランザクションも台帳に適用できないため、強力な安全性保証を維持しながらネットワークが継続的に進行することを保証する。
Ripple Protocol Consensus Algorithm
Ripple Protocol Consensus Algorithm (RPCA) เริ่มต้นจากการที่เซิร์ฟเวอร์แต่ละตัวรวบรวมธุรกรรมที่ถูกต้องทั้งหมดที่ตนพบและยังไม่ถูกนำไปใช้ ให้เป็นธุรกรรมผู้สมัคร จากนั้นเซิร์ฟเวอร์จะทำตามโปรโตคอลหลายรอบ โดยทำงานแบบวนซ้ำเพื่อให้ได้ข้อตกลงร่วมกันบนชุดธุรกรรมที่จะนำไปใช้กับ ledger ปัจจุบัน ในแต่ละรอบ เซิร์ฟเวอร์จะยื่นข้อเสนอที่ประกอบด้วยธุรกรรมที่ตนเชื่อว่าควรถูกบรรจุใน ledger ถัดไป
ระหว่างแต่ละรอบของฉันทามติ เซิร์ฟเวอร์จะสื่อสารข้อเสนอของตนไปยังเซิร์ฟเวอร์อื่นใน Unique Node List (UNL) ของตน แล้วจึงคำนวณว่าธุรกรรมใดปรากฏในสัดส่วนถึงเกณฑ์ของข้อเสนอ ตอนเริ่มต้นเกณฑ์นี้ตั้งไว้ที่ 50% หมายความว่าธุรกรรมต้องปรากฏในข้อเสนอจากอย่างน้อยครึ่งหนึ่งของ UNL ของเซิร์ฟเวอร์ จึงจะถูกพิจารณาในรอบถัดไป เมื่อฉันทามติดำเนินผ่านหลายรอบ เกณฑ์นี้จะเพิ่มขึ้นทีละขั้น (โดยทั่วไปเป็น 60%, 70% และสุดท้าย 80%)
เมื่อธุรกรรมใดถึงเกณฑ์ supermajority ที่ 80% ของการสนับสนุนภายใน UNL ของเซิร์ฟเวอร์ ธุรกรรมนั้นจะถูกใส่ไว้ในข้อเสนอสำหรับรอบฉันทามติสุดท้ายของเซิร์ฟเวอร์ ธุรกรรมทั้งหมดที่ถึงเกณฑ์นี้ทั่วทั้งเครือข่ายจะถูกนำไปใช้กับ ledger จากนั้น ledger จะถูก hash และลงลายมือชื่อเชิงคริปโตกราฟี ledger ที่ผ่านการตรวจสอบใหม่นี้จะกลายเป็น last-closed ledger และกระบวนการจะเริ่มใหม่กับชุดธุรกรรมผู้สมัครถัดไป
กระบวนการฉันทามติโดยทั่วไปเสร็จสิ้นใน 5 วินาทีหรือน้อยกว่า โดยธุรกรรมส่วนใหญ่ต้องใช้เพียงหนึ่งรอบเพื่อถึงเกณฑ์ supermajority ธุรกรรมที่ยังไม่ถึงฉันทามติในรอบหนึ่งจะคงสถานะผู้สมัครสำหรับรอบถัดไป การออกแบบนี้ทำให้เครือข่ายเดินหน้าต่อเนื่องพร้อมรักษา safety ที่แข็งแรง เนื่องจากไม่มีธุรกรรมใดถูกนำเข้า ledger ได้หากไม่มีการสนับสนุนระดับ supermajority จาก validator ที่เชื่อถือได้
Formal Analysis of Convergence
RPCAの正確性は、ネットワーク内の異なるノードが選択したUNL間の重複に決定的に依存する。UNL_iをノードiのUnique Node Listとし、UNL_i ∩ UNL_jをUNL_iとUNL_jの両方に含まれるノードの集合とする。ネットワークが合意を維持するためには、任意の2つのノードiとjに対して、それらのUNLの共通部分がいずれかのUNLの最大サイズに対して十分に大きい必要がある。
具体的には、プロトコルはすべてのノードペアiとjに対して|UNL_i ∩ UNL_j| / max(|UNL_i|, |UNL_j|) 1/5である場合に安全性を保証する。この条件は、Byzantineノードがネットワークの異なる部分に異なる合意決定をさせようとしても、信頼ノードの重複がフォークを防止することを保証する。この条件が成立し、いずれのUNLにおいてもByzantineノードが1/5未満であれば、すべての正しいノードは同じ合意決定に達する。
形式的証明は、2つのノードが異なる合意決定に達する可能性がある場合、一方のノードの最終台帳には含まれるがもう一方には含まれないトランザクションTが存在しなければならないことを示すことによって進む。これが発生するためには、Tが最初のノードのUNLで80%の支持を達成しているが、2番目のノードのUNLでは80%未満の支持しか得ていない必要がある。しかし、重複要件とByzantineノードの制約を考慮すると、このシナリオは不可能であることが示される:TがUNL_iで80%の支持を達成した場合、重複条件を満たすいかなるUNL_jでも少なくとも60%の支持を達成しなければならず、十分な合意ラウンドを経れば80%に収束するか、両方のノードによって拒否される。
活性の性質——合意が最終的に達成されること——は、包含のための閾値が合意ラウンドを通じて決定論的に増加するという観察から導かれる。Byzantineノードとネットワーク遅延が存在しても、プロトコルは誠実なノードの絶対多数が支持するトランザクションが最終的に含まれ、そのような支持を欠くトランザクションが除外されることを保証する。合意のための限られた時間(通常5秒)は、決済システムアプリケーションに適した実用的な活性保証を提供する。
Formal Analysis of Convergence
ความถูกต้องของ RPCA ขึ้นอยู่กับระดับการทับซ้อนของ UNL ที่โหนดต่าง ๆ ในเครือข่ายเลือกอย่างมีนัยสำคัญ กำหนดให้ UNL_i คือ unique node list ของโหนด i และ UNL_i ∩ UNL_j คือเซตของโหนดที่อยู่ทั้งใน UNL_i และ UNL_j เพื่อให้เครือข่ายคงฉันทามติได้ ต้องมีเงื่อนไขว่าคู่โหนดใด ๆ i และ j มีขนาดจุดตัดของ UNL มากพอเมื่อเทียบกับขนาดที่ใหญ่ที่สุดของ UNL ทั้งสอง
โดยเฉพาะ โปรโตคอลรับประกัน safety เมื่อ |UNL_i ∩ UNL_j| / max(|UNL_i|, |UNL_j|) 1/5 สำหรับทุกคู่โหนด i และ j เงื่อนไขนี้ทำให้แม้โหนด Byzantine พยายามผลักดันให้ส่วนต่าง ๆ ของเครือข่ายตัดสินใจไม่ตรงกัน การทับซ้อนของโหนดที่เชื่อถือได้ก็ยังป้องกันการแตก fork ได้ หากเงื่อนไขนี้เป็นจริงและสัดส่วนโหนด Byzantine ใน UNL ใด ๆ ต่ำกว่า 1/5 โหนดที่ถูกต้องทั้งหมดจะลงเอยด้วยการตัดสินใจฉันทามติแบบเดียวกัน
หลักฐานเชิงรูปแบบดำเนินโดยแสดงว่า หากสองโหนดสามารถไปถึงการตัดสินใจฉันทามติที่ต่างกันได้ จะต้องมีธุรกรรม T ที่อยู่ใน ledger สุดท้ายของโหนดหนึ่งแต่ไม่อยู่ในอีกโหนดหนึ่ง การเกิดเหตุเช่นนี้ต้องการให้ T ได้รับการสนับสนุน 80% ใน UNL ของโหนดแรก แต่ต่ำกว่า 80% ใน UNL ของโหนดที่สอง อย่างไรก็ตาม ภายใต้ข้อกำหนดการทับซ้อนและข้อจำกัดจำนวนโหนด Byzantine สถานการณ์นี้พิสูจน์ได้ว่าเป็นไปไม่ได้: หาก T ได้ 80% ใน UNL_i ก็ต้องได้อย่างน้อย 60% ใน UNL_j ที่เข้าเงื่อนไขการทับซ้อน และเมื่อมีรอบฉันทามติเพียงพอ ค่าดังกล่าวจะลู่เข้าไปที่ 80% หรือถูกปฏิเสธโดยทั้งสองโหนด
คุณสมบัติ liveness ซึ่งหมายถึงการได้ฉันทามติในที่สุด มาจากข้อเท็จจริงว่าเกณฑ์การรวมธุรกรรมเพิ่มขึ้นแบบเชิงกำหนดผ่านแต่ละรอบฉันทามติ แม้จะมีโหนด Byzantine และความหน่วงเครือข่าย โปรโตคอลยังคงรับประกันว่าธุรกรรมที่ได้รับการสนับสนุนระดับ supermajority จากโหนดสุจริตจะถูกบรรจุในที่สุด ส่วนธุรกรรมที่ขาดการสนับสนุนดังกล่าวจะถูกตัดออก เวลาฉันทามติที่มีขอบเขต (โดยทั่วไปประมาณ 5 วินาที) จึงให้การรับประกัน liveness เชิงปฏิบัติที่เหมาะกับงานระบบชำระเงิน
Unique Node Lists
Unique Node List(UNL)は、RPCAを他の合意アルゴリズムと区別する根本的な構成要素である。Rippleネットワークの各ノードは、ネットワークを欺くために共謀しないと信頼する他のノードからなるUNLを維持する。重要なのは、この信頼がグローバルではなくローカルであるということである:異なるノードは異なるUNLを持つことができ、グローバルに合意された検証者セットは要求されない。この設計により、分散化を維持しながらネットワークが有機的に拡張できる。
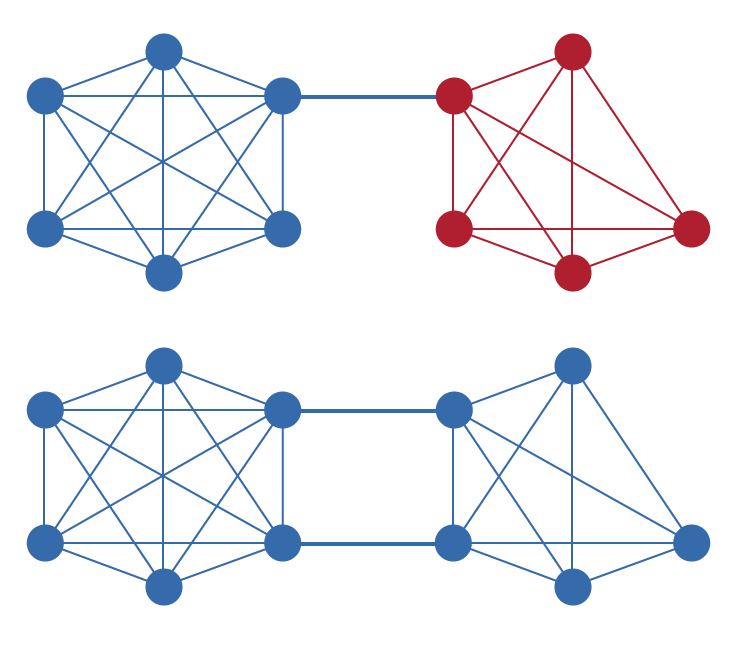
UNLは、プルーフ・オブ・ワークなしにSybil攻撃防止メカニズムとして機能する。単純な投票システムでは、攻撃者は不均衡な影響力を得るために多数の偽名ノードを作成できる。各ノードが信頼する他のノードを明示的に選択することを要求することにより、RPCAは、それらのアイデンティティが既存のノードを説得してUNLに追加されない限り、追加のアイデンティティを作成しても何の利点も得られないことを保証する。これにより、Sybil耐性の問題は計算的支出から評判と信頼関係に移行する。
ネットワークが正しく機能するためには、形式的分析で説明したように、UNLが十分な重複を持つように選択されなければならない。実際には、各ノード運営者がUNL選択において自律性を持ちながらも、ネットワークの他の部分でも信頼されている検証者をリストに含めることを保証しなければならないことを意味する。Rippleは多様なエンティティが運営する検証者からなるデフォルトUNLを提供するが、ノード運営者は独自の信頼評価に基づいてこのリストを自由に変更できる。
UNLメカニズムはまた、段階的な分散化への自然な道筋を提供する。ネットワークの初期段階では、安定性と信頼性を確保するために、より集中化された検証者セットが適切かもしれない。ネットワークが成熟し、より多様な運営者がその信頼性を実証するにつれて、UNLはセキュリティ特性を損なうことなく、ネットワークの耐障害性と分散化を高めるより広範な検証者セットを含むように進化できる。
Unique Node Lists
Unique Node List (UNL) เป็นองค์ประกอบหลักของ RPCA ที่ทำให้แตกต่างจากอัลกอริทึมฉันทามติอื่น ๆ แต่ละโหนดในเครือข่าย Ripple จะดูแล UNL ของตนเอง ซึ่งประกอบด้วยโหนดอื่นที่ตนเชื่อว่าจะไม่สมรู้ร่วมคิดเพื่อฉ้อโกงเครือข่าย ประเด็นสำคัญคือความไว้วางใจนี้เป็นแบบเฉพาะที่ ไม่ใช่แบบทั่วโลก: โหนดต่างกันสามารถมี UNL ต่างกันได้ และไม่จำเป็นต้องมีชุด validator เดียวที่ทุกฝ่ายตกลงร่วมกันทั้งเครือข่าย การออกแบบนี้ช่วยให้เครือข่ายขยายตัวอย่างเป็นธรรมชาติพร้อมรักษาความเป็นกระจายอำนาจ
UNL ทำหน้าที่เป็นกลไกป้องกันการโจมตี Sybil โดยไม่ต้องพึ่ง proof-of-work ในระบบโหวตแบบง่าย ผู้โจมตีสามารถสร้างตัวตนปลอมจำนวนมากเพื่อเพิ่มอิทธิพลอย่างไม่สมส่วน แต่เมื่อ RPCA บังคับให้แต่ละโหนดต้องเลือกอย่างชัดเจนว่าจะเชื่อโหนดใด การสร้างตัวตนเพิ่มจึงไม่ให้ประโยชน์ เว้นแต่ตัวตนเหล่านั้นจะโน้มน้าวโหนดที่มีอยู่ให้เพิ่มเข้ามาใน UNL ได้ ปัญหาการต้านทาน Sybil จึงย้ายจากการใช้ทรัพยากรคำนวณไปสู่เรื่องชื่อเสียงและความสัมพันธ์เชิงความไว้วางใจ
เพื่อให้เครือข่ายทำงานได้อย่างถูกต้อง UNL ต้องถูกเลือกให้มีการทับซ้อนเพียงพอตามที่ระบุไว้ใน formal analysis ในทางปฏิบัติ แม้ผู้ดำเนินการโหนดแต่ละรายจะมีอิสระในการเลือก UNL ของตนเอง แต่ต้องทำให้แน่ใจว่ารายชื่อดังกล่าวรวม validator ที่ส่วนอื่นของเครือข่ายไว้วางใจด้วย Ripple มี UNL เริ่มต้นที่ประกอบด้วย validator จากหลายองค์กรที่หลากหลาย แต่ผู้ดำเนินการโหนดสามารถปรับเปลี่ยนรายชื่อตามการประเมินความไว้วางใจของตนเองได้
กลไก UNL ยังเปิดเส้นทางตามธรรมชาติสู่การกระจายอำนาจแบบค่อยเป็นค่อยไป ในช่วงแรกของเครือข่าย การมีชุด validator ที่รวมศูนย์กว่าอาจเหมาะสมต่อความเสถียรและความน่าเชื่อถือ เมื่อเครือข่ายเติบโตและผู้ดำเนินการที่หลากหลายพิสูจน์ความน่าเชื่อถือได้มากขึ้น UNL ก็สามารถพัฒนาให้รวม validator ที่กว้างขึ้น เพิ่มทั้งความยืดหยุ่นและความเป็นกระจายอำนาจ โดยไม่ลดทอนคุณสมบัติความปลอดภัย
Simulation Code
RPCAの理論的分析を検証し、さまざまな条件下でのパフォーマンスを評価するために、カスタムビルドのシミュレーションソフトウェアを使用して大規模なシミュレーションが実施された。シミュレーションフレームワークは、それぞれ独自のUNLを維持し合意プロトコルに参加するノードのネットワークをモデル化する。コードは、トランザクション提案、閾値が増加する投票ラウンド、台帳検証を含む完全なRPCAアルゴリズムを実装している。
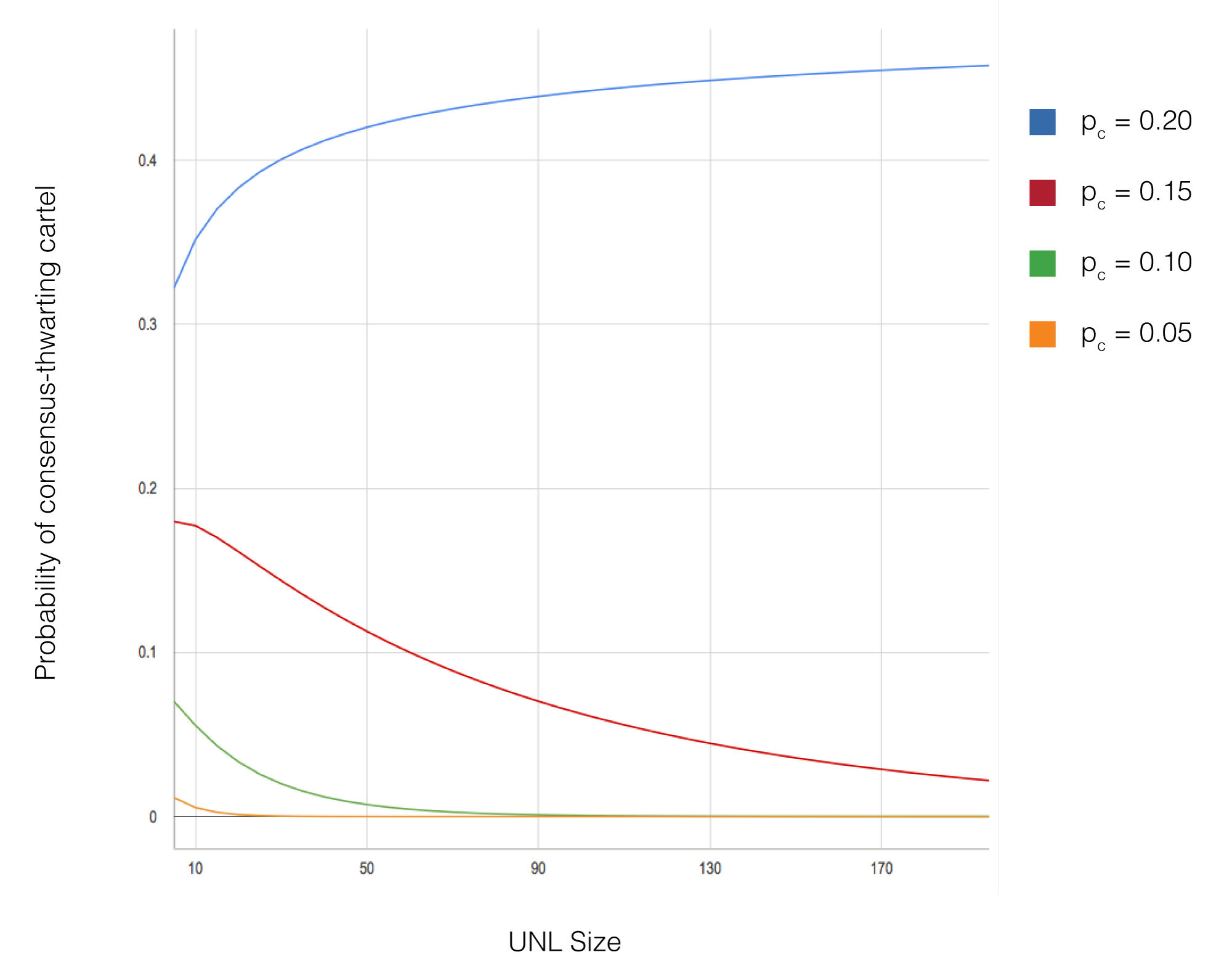
シミュレーションで変更された主要なパラメータには、ネットワークサイズ(10から1,000ノード)、Byzantineノードの割合(0%から20%)、UNLサイズ(通常5から50ノード)、およびネットワークトポロジー構成が含まれる。各パラメータ構成に対して、結果の統計的妥当性を確保するために異なるランダムシードを使用して複数のシミュレーション実行が行われた。シミュレーションは合意遅延、フォーク確率、トランザクションスループットを含むメトリクスを追跡した。
シミュレーション結果は、収束と安全性に関する理論的予測を確認している。UNL重複条件が満たされ、Byzantineノードが各UNLの20%未満であるすべての構成において、ネットワークはフォークなしに正常に合意に達した。合意遅延はネットワークサイズに関係なく一貫して低く維持され(通常3〜5秒のシミュレーション時間内に完了)、アルゴリズムのスケーラビリティを実証した。合意を妨害しようと積極的に試みる15%のByzantineノードが存在しても、UNL重複要件が満たされている限り、ネットワークは正確性を維持した。
追加のシミュレーションは、ネットワーク分割、UNL構成の突然の変更、Byzantineノードによる協調攻撃を含むエッジケースと障害シナリオを探索した。これらのシミュレーションはプロトコルの堅牢性に関する洞察を提供し、UNL選択とネットワーク運用に関する推奨ベストプラクティスの策定に寄与した。独立した検証とさらなる研究を可能にするため、完全なシミュレーションコードが公開されている。
Simulation Code
เพื่อยืนยันการวิเคราะห์เชิงทฤษฎีของ RPCA และประเมินประสิทธิภาพภายใต้เงื่อนไขที่หลากหลาย ได้มีการจำลองอย่างครอบคลุมด้วยซอฟต์แวร์จำลองที่พัฒนาขึ้นเฉพาะทาง กรอบการจำลองจำลองเครือข่ายของโหนดซึ่งแต่ละโหนดดูแล UNL ของตนเองและเข้าร่วมในโปรโตคอลฉันทามติ โค้ดครอบคลุมการทำงาน RPCA แบบครบถ้วน ทั้งการเสนอธุรกรรม รอบโหวตที่เพิ่มเกณฑ์ตามลำดับ และการตรวจสอบ ledger
พารามิเตอร์สำคัญที่ถูกปรับในการจำลอง ได้แก่ ขนาดเครือข่าย (ตั้งแต่ 10 ถึง 1,000 โหนด), สัดส่วนโหนด Byzantine (0% ถึง 20%), ขนาด UNL (โดยทั่วไป 5 ถึง 50 โหนด), และการกำหนด topology ของเครือข่าย สำหรับแต่ละชุดพารามิเตอร์ มีการรันจำลองหลายครั้งด้วย random seed ที่ต่างกันเพื่อรับรองความน่าเชื่อถือเชิงสถิติของผลลัพธ์ การจำลองติดตามตัวชี้วัดสำคัญ เช่น ความหน่วงฉันทามติ ความน่าจะเป็นของการเกิด fork และ throughput ของธุรกรรม
ผลการจำลองยืนยันการคาดการณ์ทางทฤษฎีเกี่ยวกับการลู่เข้าและ safety ในทุกการกำหนดค่าที่เงื่อนไขการทับซ้อนของ UNL เป็นจริง และสัดส่วนโหนด Byzantine ต่ำกว่า 20% ของแต่ละ UNL เครือข่ายสามารถบรรลุฉันทามติได้โดยไม่เกิด fork ความหน่วงฉันทามติคงอยู่ในระดับต่ำอย่างสม่ำเสมอ (โดยทั่วไปเสร็จในเวลา 3-5 วินาทีจำลอง) ไม่ขึ้นกับขนาดเครือข่าย ซึ่งแสดงถึงความสามารถในการขยายตัวของอัลกอริทึม แม้มีโหนด Byzantine 15% พยายามรบกวนฉันทามติอย่างจริงจัง เครือข่ายก็ยังคง correctness ได้ ตราบใดที่เงื่อนไขการทับซ้อนของ UNL ยังถูกต้อง
การจำลองเพิ่มเติมยังครอบคลุมกรณีขอบและสถานการณ์ล้มเหลว เช่น การแบ่งพาร์ทิชันของเครือข่าย การเปลี่ยนองค์ประกอบ UNL อย่างฉับพลัน และการโจมตีแบบประสานงานโดยโหนด Byzantine ผลลัพธ์เหล่านี้ให้ข้อมูลเชิงลึกเกี่ยวกับความทนทานของโปรโตคอล และช่วยกำหนดแนวปฏิบัติที่แนะนำสำหรับการเลือก UNL และการปฏิบัติการเครือข่าย โค้ดจำลองทั้งหมดถูกเผยแพร่เพื่อรองรับการตรวจสอบอิสระและการวิจัยต่อยอด
Discussion
ビットコインのプルーフ・オブ・ワーク合意と比較して、RPCAは決済システムアプリケーションにいくつかの重要な利点を提供する。最も注目すべきは、合意遅延が40〜60分(高額ビットコイン取引に通常推奨される時間)から約5秒に短縮されることである。この改善により、RPCAはほぼ即時の決済が必要なPOS(販売時点)やその他のアプリケーションに適している。さらに、RPCAはプルーフ・オブ・ワークと比較して最小限の計算リソースしか必要とせず、ビットコインマイニングに伴う膨大なエネルギー消費を排除する。
しかし、これらの利点には異なる信頼仮定が伴う。ビットコインのセキュリティが、いかなる攻撃者もネットワークの計算能力の50%以上を制御しないという仮定のみに依存するのに対し、RPCAはノードが十分な重複を持つUNLを選択し、ByzantineノードがこれらのUNL内で閾値を超えないことを要求する。これにより、慎重な信頼決定を行う責任の一部がノード運営者に移る。実際には、参加機関が既存の信頼関係を持つ多くの決済システムユースケースにおいて、このトレードオフは許容可能である。
ネットワークトポロジーとUNL選択戦略は、合意システムの特性に大きく影響する。すべてのノードがUNLに同じ検証者を含む高度に集中化されたトポロジーは安全性を最大化するが、それらの検証者が利用不可になった場合、活性が低下する可能性がある。逆に、UNLの重複が最小限の高度に分散化されたトポロジーは活性を改善する可能性があるが、重複が疎になりすぎると合意障害のリスクがある。最適なバランスを見つけるには、特定のデプロイメントシナリオとリスク許容度の慎重な考慮が必要である。
将来の研究では、分散化を最大化しながら重複要件を自動的に維持する適応的UNL選択アルゴリズム、観察された検証者の行動に基づいてノードがUNLを動的に調整するメカニズム、そしてさらに高い割合のByzantineノードを許容できる合意アルゴリズムの拡張を探求できる可能性がある。これらの強化により、大規模分散型決済システムに対するRPCAの堅牢性と適用可能性がさらに向上する可能性がある。
Discussion
เมื่อเทียบกับฉันทามติแบบ proof-of-work ของ Bitcoin แล้ว RPCA มีข้อได้เปรียบสำคัญหลายประการสำหรับงานระบบการชำระเงิน จุดเด่นที่สุดคือความหน่วงฉันทามติลดลงจาก 40-60 นาที (เวลาที่มักแนะนำสำหรับธุรกรรม Bitcoin มูลค่าสูง) เหลือประมาณ 5 วินาที การปรับปรุงนี้ทำให้ RPCA เหมาะกับงาน point-of-sale และกรณีใช้งานอื่นที่ต้องการการชำระบัญชีเกือบทันที นอกจากนี้ RPCA ใช้ทรัพยากรคำนวณต่ำมากเมื่อเทียบกับ proof-of-work จึงลดปัญหาการใช้พลังงานมหาศาลที่สัมพันธ์กับการขุด Bitcoin
อย่างไรก็ตาม ข้อได้เปรียบดังกล่าวมาพร้อมสมมติฐานความไว้วางใจที่ต่างออกไป ความปลอดภัยของ Bitcoin อาศัยเพียงสมมติฐานว่าไม่มีผู้โจมตีรายใดควบคุมกำลังคำนวณเกิน 50% ของเครือข่าย ขณะที่ RPCA ต้องการให้โหนดเลือก UNL ที่มีการทับซ้อนเพียงพอ และจำนวนโหนด Byzantine ไม่เกินเกณฑ์ภายใน UNL เหล่านั้น สิ่งนี้ย้ายความรับผิดชอบบางส่วนไปยังผู้ดำเนินการโหนดให้ตัดสินใจด้านความไว้วางใจอย่างรอบคอบ ในทางปฏิบัติ trade-off นี้ยอมรับได้สำหรับหลายกรณีใช้งานด้านการชำระเงินที่องค์กรผู้เข้าร่วมมีความสัมพันธ์ความไว้วางใจกันอยู่แล้ว
topology ของเครือข่ายและกลยุทธ์การเลือก UNL ส่งผลอย่างมีนัยสำคัญต่อคุณสมบัติของระบบฉันทามติ topology ที่รวมศูนย์สูง ซึ่งทุกโหนดใช้ validator ชุดเดียวกันใน UNL จะเพิ่ม safety ได้สูงสุด แต่สามารถลด liveness ได้หาก validator ชุดนั้นไม่พร้อมใช้งาน ในทางกลับกัน topology ที่กระจายอำนาจสูงและมีการทับซ้อน UNL ต่ำ อาจช่วย liveness แต่เสี่ยงต่อความล้มเหลวของฉันทามติหากการทับซ้อนเบาบางเกินไป การหาจุดสมดุลที่เหมาะสมจึงต้องพิจารณาร่วมกันทั้งบริบทการใช้งานจริงและระดับความเสี่ยงที่ยอมรับได้
งานในอนาคตอาจสำรวจอัลกอริทึมเลือก UNL แบบปรับตัวที่รักษาเงื่อนไขการทับซ้อนโดยอัตโนมัติพร้อมเพิ่มความเป็นกระจายอำนาจให้มากที่สุด กลไกที่ให้โหนดปรับ UNL แบบไดนามิกจากพฤติกรรม validator ที่สังเกตได้ และส่วนขยายของอัลกอริทึมฉันทามติที่ทนต่อสัดส่วนโหนด Byzantine ที่สูงขึ้นได้อีก การพัฒนาเหล่านี้จะช่วยเพิ่มทั้งความแข็งแรงและความสามารถในการประยุกต์ใช้ RPCA ในระบบการชำระเงินแบบกระจายขนาดใหญ่
Conclusion
Rippleプロトコル合意アルゴリズムは、決済システムのための分散型合意における重要な進歩を表している。すべてのノード間のグローバルな合意を要求する代わりに、集合的に信頼されたサブネットワークを活用することにより、RPCAはByzantine障害に対する強力な保証を維持しながら数秒で合意を達成する。形式的分析は、UNLが十分な重複で選択され、Byzantineノードが閾値以下に維持される限り、ネットワークがフォークなしに正しい合意に達することを実証している。
本研究の実用的な意味合いは、Ripple決済ネットワークを超えて広がる。RPCAは、合意遅延とセキュリティ保証の間の従来のトレードオフが、慎重なプロトコル設計とローカルな信頼関係の利用を通じて克服できることを示している。このアプローチは、低い遅延が重要であり参加者が既存の信頼関係を持つ他の分散システム、例えば銀行間決済システム、サプライチェーン追跡、その他の金融インフラアプリケーションに適用可能であると考えられる。
本番システムにおけるRPCAの展開は、アルゴリズムのパフォーマンス特性と堅牢性を検証した。Rippleネットワークは、一貫した3〜5秒の合意遅延で毎秒数千のトランザクションを処理しており、理論的特性が実世界の運用に効果的に反映されることを実証している。ネットワークが進化を続け、多様な運営者からの追加の検証者を組み込むにつれ、分散型合意システムがスケールにおいてセキュリティとパフォーマンスの両方を維持できる方法の実用的な事例を提供している。
Conclusion
Ripple Protocol Consensus Algorithm เป็นความก้าวหน้าสำคัญของฉันทามติแบบกระจายสำหรับระบบการชำระเงิน ด้วยการใช้เครือข่ายย่อยที่ได้รับความไว้วางใจร่วมกัน แทนการบังคับให้ทุกโหนดต้องตกลงกันแบบทั่วทั้งเครือข่าย RPCA จึงบรรลุฉันทามติได้ภายในไม่กี่วินาที พร้อมคงการรับประกันที่แข็งแรงต่อความล้มเหลวแบบ Byzantine การวิเคราะห์เชิงรูปแบบยืนยันว่า หาก UNL ถูกเลือกให้มีการทับซ้อนเพียงพอ และจำนวนโหนด Byzantine อยู่ต่ำกว่าเกณฑ์ เครือข่ายจะบรรลุฉันทามติที่ถูกต้องโดยไม่เกิด fork
นัยเชิงปฏิบัติของงานนี้ไม่ได้จำกัดอยู่แค่เครือข่ายการชำระเงินของ Ripple เท่านั้น RPCA แสดงให้เห็นว่าการแลกเปลี่ยนแบบดั้งเดิมระหว่างความหน่วงฉันทามติกับการรับประกันความปลอดภัย สามารถก้าวข้ามได้ด้วยการออกแบบโปรโตคอลอย่างรอบคอบและการใช้ความสัมพันธ์ความไว้วางใจแบบเฉพาะที่ แนวทางนี้มีศักยภาพสำหรับระบบแบบกระจายอื่นที่ต้องการความหน่วงต่ำและมีผู้เข้าร่วมที่มีความไว้วางใจต่อกันอยู่แล้ว เช่น ระบบชำระบัญชีระหว่างธนาคาร การติดตามห่วงโซ่อุปทาน และงานโครงสร้างพื้นฐานทางการเงินอื่น ๆ
การนำ RPCA ไปใช้งานจริงในระบบ production ได้ยืนยันทั้งสมรรถนะและความทนทานของอัลกอริทึม เครือข่าย Ripple ประมวลผลธุรกรรมได้หลายพันรายการต่อวินาที พร้อมความหน่วงฉันทามติที่สม่ำเสมอที่ 3-5 วินาที แสดงให้เห็นว่าคุณสมบัติเชิงทฤษฎีสามารถแปลงเป็นผลลัพธ์จริงได้อย่างมีประสิทธิภาพ เมื่อเครือข่ายพัฒนาอย่างต่อเนื่องและเพิ่ม validator จากผู้ดำเนินการที่หลากหลายมากขึ้น RPCA จึงเป็นตัวอย่างเชิงปฏิบัติของระบบฉันทามติแบบกระจายอำนาจที่รักษาได้ทั้งความปลอดภัยและประสิทธิภาพในระดับสเกลใหญ่
References
Lamport, L., Shostak, R., and Pease, M. (1982). "The Byzantine Generals Problem." ACM Transactions on Programming Languages and Systems, 4(3):382-401. この画期的な論文は、障害のあるコンポーネントを持つ分散システムにおいて合意に達する問題を定式化し、Byzantine fault-tolerantシステムの理論的基盤を確立した。
Castro, M., and Liskov, B. (1999). "Practical Byzantine Fault Tolerance." Proceedings of the Third Symposium on Operating Systems Design and Implementation (OSDI). この研究はPBFTを導入し、Byzantine fault toleranceが実用的なパフォーマンスで達成できることを実証したが、O(n^2)の通信計算量がスケーラビリティを制限した。
Nakamoto, S. (2008). "Bitcoin: A Peer-to-Peer Electronic Cash System." このホワイトペーパーは、デジタル通貨における二重支出問題の解決策としてプルーフ・オブ・ワーク合意を導入し、高い遅延とエネルギー消費を代償として、信頼できる当事者なしに分散型合意を可能にした。
Lamport, L. (1998). "The Part-Time Parliament." ACM Transactions on Computer Systems, 16(2):133-169. この論文は、クラッシュ障害の下で非同期システムにおいて合意を達成するPaxosアルゴリズムを提示し、その後の合意プロトコル設計に影響を与えた。
Fischer, M. J., Lynch, N. A., and Paterson, M. S. (1985). "Impossibility of Distributed Consensus with One Faulty Process." Journal of the ACM, 32(2):374-382. FLP不可能性結果は、非同期システムにおいて合意アルゴリズムが達成できることの根本的な限界を確立し、実用的な合意プロトコルの設計空間を形成した。
References
Lamport, L., Shostak, R., และ Pease, M. (1982). "The Byzantine Generals Problem." ACM Transactions on Programming Languages and Systems, 4(3):382-401. งานคลาสสิกนี้ได้ทำให้ปัญหาการบรรลุฉันทามติในระบบกระจายที่มีองค์ประกอบผิดพลาดเป็นรูปแบบทางการ และวางรากฐานเชิงทฤษฎีให้กับระบบที่ทนต่อความผิดพลาดแบบ Byzantine
Castro, M., และ Liskov, B. (1999). "Practical Byzantine Fault Tolerance." Proceedings of the Third Symposium on Operating Systems Design and Implementation (OSDI). งานนี้แนะนำ PBFT และแสดงให้เห็นว่าความทนทานต่อ Byzantine fault สามารถทำได้จริงในทางปฏิบัติ แม้จะมีความซับซ้อนด้านการสื่อสาร O(n^2) ที่จำกัดการขยายตัว
Nakamoto, S. (2008). "Bitcoin: A Peer-to-Peer Electronic Cash System." เอกสาร whitepaper นี้เสนอฉันทามติแบบ proof-of-work เพื่อแก้ปัญหา double-spending ในสกุลเงินดิจิทัล ทำให้เกิดฉันทามติแบบกระจายศูนย์โดยไม่ต้องพึ่งผู้มีอำนาจที่เชื่อถือได้ แต่แลกมาด้วยความหน่วงสูงและการใช้พลังงานมาก
Lamport, L. (1998). "The Part-Time Parliament." ACM Transactions on Computer Systems, 16(2):133-169. บทความนี้นำเสนออัลกอริทึม Paxos ซึ่งบรรลุฉันทามติในระบบอะซิงโครนัสภายใต้ความล้มเหลวแบบ crash และมีอิทธิพลต่อการออกแบบโปรโตคอลฉันทามติในเวลาต่อมา
Fischer, M. J., Lynch, N. A., และ Paterson, M. S. (1985). "Impossibility of Distributed Consensus with One Faulty Process." Journal of the ACM, 32(2):374-382. ผลลัพธ์ความเป็นไปไม่ได้ของ FLP ได้กำหนดขอบเขตพื้นฐานของสิ่งที่อัลกอริทึมฉันทามติทำได้ในระบบอะซิงโครนัส และกำหนดทิศทางพื้นที่ออกแบบของโปรโตคอลฉันทามติเชิงปฏิบัติ




