
Ripple协议共识算法
Abstract
Mặc dù đã có nhiều thuật toán đồng thuận cho Bài toán các tướng Byzantine, đặc biệt trong bối cảnh hệ thống thanh toán phân tán, nhiều thuật toán vẫn gặp độ trễ cao do yêu cầu tất cả các nút trong mạng phải giao tiếp đồng bộ. Trong công trình này, chúng tôi trình bày một thuật toán đồng thuận mới vượt qua yêu cầu đó bằng cách tận dụng các mạng con được tin cậy tập thể bên trong mạng lớn hơn. Chúng tôi chỉ ra rằng "niềm tin" cần thiết để ngăn chặn tấn công Sybil thực chất không phải là toàn cục, mà là cục bộ theo từng nút trong mạng.
Thuật toán đồng thuận giao thức Ripple (RPCA) được áp dụng vài giây một lần bởi tất cả các nút để duy trì tính đúng đắn và sự nhất quán của mạng. Khi đạt đồng thuận, sổ cái hiện tại được coi là "đã đóng" và trở thành sổ cái đóng gần nhất. Thuật toán này khác biệt ở chỗ đạt đồng thuận với độ trễ thấp trong khi vẫn duy trì các bảo đảm mạnh trước lỗi Byzantine, phù hợp cho các hệ thống thanh toán tài chính thời gian thực.
Abstract
虽然存在多种针对Byzantine Generals Problem的共识算法,特别是与分布式支付系统相关的算法,但其中许多都因网络中所有节点需要同步通信的要求而导致高延迟问题。在本研究中,我们提出了一种新颖的共识算法,通过利用更大网络内的集体信任子网络来规避这一要求。我们证明,防止Sybil攻击所需的"信任"实际上不是全局性的,而是网络中每个节点的局部性的。
Ripple协议共识算法(RPCA)由所有节点每隔几秒应用一次,以维护网络的正确性和一致性。一旦达成共识,当前账本被视为"关闭",成为最后关闭的账本(last-closed ledger)。该算法的独特之处在于,它在维持对Byzantine故障的强大保障的同时实现了低延迟共识,使其适用于实时金融结算系统。
Introduction
Một hệ thống thanh toán phân tán phải triển khai thuật toán đồng thuận để xử lý thanh toán chính xác và kịp thời ngay cả khi có tác nhân lỗi hoặc độc hại. Bitcoin đạt đồng thuận bằng proof-of-work, yêu cầu tất cả các nút tiêu tốn tài nguyên tính toán để giải các bài toán mật mã. Dù cách tiếp cận này cung cấp bảo đảm bảo mật mạnh, nó có các hạn chế đáng kể như tiêu thụ năng lượng cao, thông lượng giao dịch thấp và độ trễ xác nhận dài, có thể kéo dài đến một giờ hoặc hơn với giao dịch giá trị cao.
Thuật toán đồng thuận giao thức Ripple đưa ra một cách tiếp cận mới cho đồng thuận phân tán mà không cần proof-of-work. Thay vào đó, các nút trong mạng cùng thống nhất trên các tập giao dịch thông qua cơ chế bỏ phiếu đạt đồng thuận chỉ trong vài giây. Cơ chế này được thiết kế riêng cho yêu cầu của một mạng thanh toán toàn cầu, nơi độ trễ thấp và thông lượng cao là điều kiện bắt buộc để triển khai thực tế.
Đổi mới cốt lõi của RPCA là không yêu cầu mọi nút trong mạng phải đồng ý trực tiếp với nhau. Thay vào đó, mỗi nút duy trì một Unique Node List (UNL) gồm các nút khác mà nó tin rằng sẽ không thông đồng. Miễn là các UNL do các nút chọn có độ chồng lấn đủ lớn và số nút lỗi thấp hơn một ngưỡng nhất định, mạng sẽ đạt đồng thuận. Cách làm này giữ được các bảo đảm bảo mật cần thiết cho hệ thống thanh toán đồng thời rút ngắn độ trễ đồng thuận xuống mức giây thay vì phút hoặc giờ.
Introduction
分布式支付系统必须实现共识算法,以便在存在故障或恶意行为者的情况下及时正确地处理支付。比特币通过工作量证明(proof-of-work)来达成共识,这要求所有节点消耗计算资源来解决密码学难题。虽然这种方法提供了强大的安全保障,但它存在显著的缺点,包括高能耗、低交易吞吐量以及对于高价值交易可能延长至一小时或更长时间的确认延迟。
Ripple协议共识算法提供了一种不需要工作量证明的分布式共识新方法。取而代之的是,网络中的节点通过在几秒内达成共识的投票过程来集体同意交易集合。这种共识机制专门为全球支付网络的需求而设计,在这些网络中,低延迟和高吞吐量对于实际部署至关重要。
RPCA的关键创新在于它不要求网络中的所有节点彼此达成一致。相反,每个节点维护一个唯一节点列表(Unique Node List, UNL),其中包含它信任不会串通的其他节点。只要节点选择的UNL具有足够的重叠,且故障节点低于阈值百分比,网络就会达成共识。这种方法在以秒而非分钟或小时来衡量共识延迟的同时,提供了支付系统所需的安全保障。
Definition of Consensus
Trong hệ thống phân tán, đồng thuận là quá trình một mạng các nút đi đến thống nhất về một trạng thái chung, bất chấp sự hiện diện của các thành phần lỗi hoặc độc hại. Một thuật toán đồng thuận phải thỏa mãn ba thuộc tính nền tảng: tính đúng đắn (không có hai nút đúng đưa ra quyết định khác nhau), sự nhất trí (mọi nút đúng đều đi đến cùng một quyết định), và tính kết thúc (mọi nút đúng cuối cùng đều đưa ra quyết định). Các thuộc tính này bảo đảm hệ thống phân tán hành xử như thể nó là một nút duy nhất và đáng tin cậy.
Khó khăn của đồng thuận đến từ tính không đáng tin cậy vốn có của hệ thống phân tán. Nút có thể gặp sự cố, thông điệp có thể bị trễ hoặc thất lạc, và nút Byzantine có thể hành xử tùy ý hoặc độc hại. Bài toán các tướng Byzantine, được Lamport, Shostak và Pease hình thức hóa, mô tả đúng thách thức này: làm thế nào một nhóm tiến trình đạt được thống nhất khi một phần có thể bị lỗi và truyền thông không đáng tin cậy?
Các kết quả cổ điển trong tính toán phân tán đặt ra giới hạn nền tảng cho những gì thuật toán đồng thuận có thể đạt được. Kết quả bất khả thi FLP cho thấy không thuật toán tất định nào có thể bảo đảm đồng thuận trong hệ bất đồng bộ nếu chỉ một nút cũng có thể lỗi. Vì vậy, các thuật toán đồng thuận thực tế phải đánh đổi giữa an toàn (không bao giờ đạt đồng thuận sai) và tính sống (luôn tiếp tục tiến triển). Proof-of-work của Bitcoin ưu tiên an toàn hơn tính sống, trong khi RPCA đạt cân bằng phù hợp hơn cho hệ thống thanh toán bằng cách hoàn tất các vòng đồng thuận trong thời gian hữu hạn mà vẫn duy trì bảo đảm an toàn mạnh dưới các giả định lỗi thực tế.
Definition of Consensus
在分布式系统中,共识是指即使存在故障或恶意参与者,节点网络也能就共享状态达成一致的过程。共识算法必须满足三个基本属性:正确性(没有两个正确的节点做出不同的决定)、一致性(所有正确的节点达成相同的决定)和终止性(所有正确的节点最终都会做出决定)。这些属性确保分布式系统表现得如同一个单一的、可靠的节点。
达成共识的挑战源于分布式系统固有的不可靠性。节点可能崩溃,消息可能延迟或丢失,Byzantine节点可能任意或恶意地行为。Lamport、Shostak和Pease形式化的Byzantine Generals Problem捕捉了这一挑战:当一部分进程可能存在故障且通信不可靠时,一组进程如何能够达成一致?
分布式计算的经典结果确立了共识算法所能达到的基本限制。FLP不可能性结果表明,如果即使一个节点可能失败,在异步系统中没有确定性算法可以保证达成共识。因此,实用的共识算法必须在安全性(永远不会达成错误的共识)和活性(始终保持进展)之间做出权衡。比特币的工作量证明优先考虑安全性而非活性,而RPCA通过在有限时间内完成共识轮次,同时在现实的故障假设下维持强大的安全性保障,从而实现了更适合支付系统的平衡。
Existing Consensus Algorithms
Nhiều thuật toán đồng thuận đã được đề xuất để giải Bài toán các tướng Byzantine trong hệ thống phân tán. Thuật toán Practical Byzantine Fault Tolerance (PBFT), do Castro và Liskov giới thiệu, có thể chịu tối đa f lỗi Byzantine trong hệ gồm 3f+1 nút. PBFT đạt đồng thuận qua nhiều vòng trao đổi thông điệp giữa tất cả các nút, với độ phức tạp truyền thông O(n^2), trong đó n là số nút. Dù PBFT có bảo đảm an toàn mạnh và độ trễ tương đối thấp với mạng nhỏ, nó không mở rộng tốt lên mạng lớn do chi phí truyền thông bậc hai.
Paxos và các biến thể của nó, do Lamport phát triển, đạt đồng thuận trong hệ bất đồng bộ nhưng giả định lỗi sập (crash) thay vì lỗi Byzantine. Paxos vận hành qua các vòng mà bên đề xuất đưa ra giá trị và bên chấp nhận bỏ phiếu. Dù có thể chịu trễ thông điệp tùy ý và lỗi sập tiến trình, Paxos cần thiết kế cẩn thận để xử lý lỗi Byzantine và có thể gặp livelock trong một số tình huống.
Thuật toán đồng thuận proof-of-work của Bitcoin theo một hướng tiếp cận khác về bản chất: làm cho tấn công Byzantine trở nên không khả thi về kinh tế. Các nút cạnh tranh giải bài toán mật mã, nút thắng sẽ đề xuất khối giao dịch tiếp theo. Cách làm này mở rộng được đến quy mô mạng tùy ý và xử lý được lỗi Byzantine, nhưng có nhược điểm nghiêm trọng: tiêu thụ năng lượng rất lớn (ước tính hơn 150 triệu USD mỗi năm cho mạng Bitcoin), độ trễ xác nhận dài (thường 40-60 phút cho giao dịch giá trị cao), và thông lượng hạn chế (khoảng 7 giao dịch mỗi giây). Các hạn chế này khiến proof-of-work không phù hợp với nhiều ứng dụng thanh toán cần quyết toán nhanh và khối lượng giao dịch cao.
Existing Consensus Algorithms
已经有多种共识算法被提出来解决分布式系统中的Byzantine Generals Problem。由Castro和Liskov引入的Practical Byzantine Fault Tolerance(PBFT)算法可以在3f+1个节点的系统中容忍最多f个Byzantine故障。PBFT通过所有节点之间的多轮消息交换来达成共识,通信复杂度为O(n^2),其中n为节点数量。虽然PBFT提供了强大的安全性保障和小型网络中相对较低的延迟,但由于二次通信开销,它无法良好地扩展到大型网络。
由Lamport开发的Paxos及其变体在异步系统中提供共识,但假设的是崩溃故障而非Byzantine故障。Paxos通过一系列轮次达成共识,其中提议者建议值,接受者进行投票。虽然Paxos可以容忍任意消息延迟和进程崩溃,但处理Byzantine故障需要精心的工程设计,并且在某些场景中可能发生活锁(livelock)。
比特币的工作量证明共识算法采取了根本不同的方法,使Byzantine攻击在经济上不可行。节点竞争解决密码学难题,获胜者提议下一个交易区块。虽然这种方法可以扩展到任意网络规模并处理Byzantine故障,但它有严重的缺点:大量的能源消耗(比特币网络估计每年超过1.5亿美元)、长确认延迟(高价值交易通常为40-60分钟)以及有限的吞吐量(大约每秒7笔交易)。这些限制使得工作量证明不适合许多需要快速结算和高交易量的支付系统应用。
Ripple Protocol Consensus Algorithm
Thuật toán Đồng thuận Giao thức Ripple (RPCA) bắt đầu khi mỗi máy chủ lấy tất cả các giao dịch hợp lệ mà nó đã thấy nhưng chưa được áp dụng làm giao dịch ứng viên. Các máy chủ sau đó tuân theo một giao thức nhiều vòng, lặp dần để đạt đồng thuận về tập giao dịch sẽ áp dụng cho sổ cái hiện tại. Trong mỗi vòng, máy chủ đưa ra đề xuất gồm các giao dịch mà nó cho rằng nên được đưa vào sổ cái tiếp theo.
Trong mỗi vòng đồng thuận, máy chủ truyền đề xuất của mình đến các máy chủ khác trong Unique Node List (UNL) của nó. Sau đó, máy chủ tính giao dịch nào xuất hiện trong một tỷ lệ ngưỡng của các đề xuất. Ban đầu ngưỡng này là 50%, nghĩa là giao dịch phải xuất hiện trong đề xuất từ ít nhất một nửa UNL của máy chủ thì mới được xét ở vòng sau. Khi đồng thuận tiến qua các vòng liên tiếp, ngưỡng này tăng dần (thường lên 60%, 70% và cuối cùng 80%).
Khi một giao dịch đạt ngưỡng siêu đa số 80% ủng hộ trong UNL của máy chủ, giao dịch đó sẽ được đưa vào đề xuất của máy chủ cho vòng đồng thuận cuối. Tất cả các giao dịch đạt ngưỡng này trên toàn mạng được áp dụng vào sổ cái, sau đó sổ cái được băm và ký bằng mật mã. Sổ cái mới được xác thực này trở thành sổ cái đóng gần nhất, và quy trình bắt đầu lại với tập giao dịch ứng viên tiếp theo.
Quy trình đồng thuận thường hoàn tất trong 5 giây hoặc ít hơn, với phần lớn giao dịch chỉ cần một vòng đồng thuận để đạt ngưỡng siêu đa số. Giao dịch chưa đạt đồng thuận trong một vòng sẽ tiếp tục là ứng viên cho các vòng sau. Thiết kế này bảo đảm mạng liên tục tiến triển trong khi vẫn giữ an toàn mạnh, vì không giao dịch nào có thể được áp dụng vào sổ cái nếu không có sự ủng hộ siêu đa số từ các validator đáng tin cậy.
Ripple Protocol Consensus Algorithm
Ripple协议共识算法(RPCA)从每个服务器收集所有尚未应用的有效交易作为候选交易开始。然后服务器遵循多轮协议,迭代地就当前账本应用的交易集达成一致。在每一轮中,服务器提出它们认为应该包含在下一个账本中的交易提案。
在每个共识轮次中,服务器将其提案传达给唯一节点列表(UNL)中的其他服务器。然后服务器计算哪些交易出现在阈值百分比以上的提案中。最初,该阈值设置为50%,意味着交易必须出现在服务器UNL中至少一半的提案中才能被考虑进入下一轮。随着共识通过连续轮次的推进,该阈值逐步提高(通常到60%、70%,最终到80%)。
当一笔交易在服务器的UNL中达到80%的绝对多数支持阈值时,它将被包含在该服务器最终共识轮次的提案中。网络中所有达到该阈值的交易被应用到账本上,账本随后被加密哈希和签名。这个新验证的账本成为最后关闭的账本,流程以下一组候选交易重新开始。
共识过程通常在5秒或更短时间内完成,大多数交易只需要一个共识轮次即可达到绝对多数阈值。在一轮中未达成共识的交易仍作为后续轮次的候选。这种设计确保网络持续推进,同时维持强大的安全性保障,因为没有任何交易可以在没有受信任验证者绝对多数支持的情况下被应用到账本上。
Formal Analysis of Convergence
Tính đúng đắn của RPCA phụ thuộc quyết định vào độ chồng lấn giữa các UNL do các nút khác nhau chọn trong mạng. Gọi UNL_i là unique node list của nút i, và UNL_i ∩ UNL_j là tập các nút xuất hiện trong cả UNL_i và UNL_j. Để mạng duy trì đồng thuận, với mọi cặp nút i và j, giao của hai UNL phải đủ lớn so với kích thước lớn hơn giữa hai UNL đó.
Cụ thể, giao thức bảo đảm an toàn khi |UNL_i ∩ UNL_j| / max(|UNL_i|, |UNL_j|) 1/5 cho mọi cặp i, j. Điều kiện này bảo đảm rằng ngay cả khi các nút Byzantine cố làm các phần khác nhau của mạng đạt các quyết định đồng thuận khác nhau, phần chồng lấn các nút đáng tin vẫn ngăn được phân nhánh. Nếu điều kiện này đúng và số nút Byzantine trong bất kỳ UNL nào nhỏ hơn 1/5, thì mọi nút đúng sẽ đi đến cùng một quyết định đồng thuận.
Chứng minh hình thức cho thấy rằng nếu hai nút có thể đi đến hai quyết định đồng thuận khác nhau, phải tồn tại một giao dịch T xuất hiện trong sổ cái cuối của một nút nhưng không có trong nút kia. Để điều này xảy ra, T phải đạt 80% ủng hộ trong UNL của nút thứ nhất nhưng dưới 80% trong UNL của nút thứ hai. Tuy nhiên, với yêu cầu chồng lấn và ràng buộc tỷ lệ Byzantine, kịch bản này là bất khả: nếu T đạt 80% trong UNL_i, nó phải đạt ít nhất 60% trong bất kỳ UNL_j nào thỏa điều kiện chồng lấn; và với đủ số vòng đồng thuận, mức này sẽ hội tụ về 80% hoặc bị cả hai nút loại bỏ.
Thuộc tính tính sống, tức đồng thuận cuối cùng sẽ đạt được, đến từ việc ngưỡng đưa vào tăng một cách tất định qua các vòng đồng thuận. Ngay cả khi có nút Byzantine và độ trễ mạng, giao thức vẫn bảo đảm các giao dịch được siêu đa số nút trung thực ủng hộ cuối cùng sẽ được đưa vào, còn các giao dịch không có mức ủng hộ đó sẽ bị loại. Thời gian đồng thuận hữu hạn (thường khoảng 5 giây) mang lại bảo đảm tính sống thực tế phù hợp với các ứng dụng thanh toán.
Formal Analysis of Convergence
RPCA的正确性关键取决于网络中不同节点选择的UNL之间的重叠。令UNL_i表示节点i的唯一节点列表,UNL_i ∩ UNL_j表示同时出现在UNL_i和UNL_j中的节点集合。为使网络维持共识,我们要求对于任意两个节点i和j,其UNL的交集相对于任一UNL的最大规模必须足够大。
具体而言,当对所有节点对i和j满足|UNL_i ∩ UNL_j| / max(|UNL_i|, |UNL_j|) 1/5时,协议保证安全性。该条件确保即使Byzantine节点试图使网络的不同部分达成不同的共识决定,受信任节点的重叠也能防止分叉。如果该条件成立且任何UNL中Byzantine节点少于1/5,则所有正确节点将达成相同的共识决定。
形式化证明通过证明如果两个节点可以达成不同的共识决定,则必定存在某笔交易T出现在一个节点的最终账本中但不在另一个节点的账本中来进行。要发生这种情况,T必须在第一个节点的UNL中获得80%的支持,但在第二个节点的UNL中获得不到80%的支持。然而,考虑到重叠要求和对Byzantine节点的约束,可以证明这种情况是不可能的:如果T在UNL_i中获得80%的支持,它必须在满足重叠条件的任何UNL_j中至少获得60%的支持,经过足够的共识轮次,这将收敛到80%或被两个节点都拒绝。
活性属性——共识最终会达成——来自于包含阈值通过共识轮次确定性地增加这一观察。即使在存在Byzantine节点和网络延迟的情况下,协议也确保由诚实节点绝对多数支持的交易最终会被包含,而缺乏此类支持的交易将被排除。共识的有限时间(通常5秒)为支付系统应用提供了实用的活性保障。
Unique Node Lists
Unique Node List (UNL) là thành phần cốt lõi của RPCA, tạo nên điểm khác biệt với các thuật toán đồng thuận khác. Mỗi nút trong mạng Ripple duy trì một UNL gồm các nút khác mà nó tin rằng sẽ không thông đồng để gian lận mạng. Điểm then chốt là niềm tin này mang tính cục bộ, không phải toàn cục: các nút khác nhau có thể có UNL khác nhau, và không có yêu cầu phải tồn tại một tập validator thống nhất toàn mạng. Thiết kế này cho phép mạng mở rộng tự nhiên trong khi vẫn giữ tính phi tập trung.
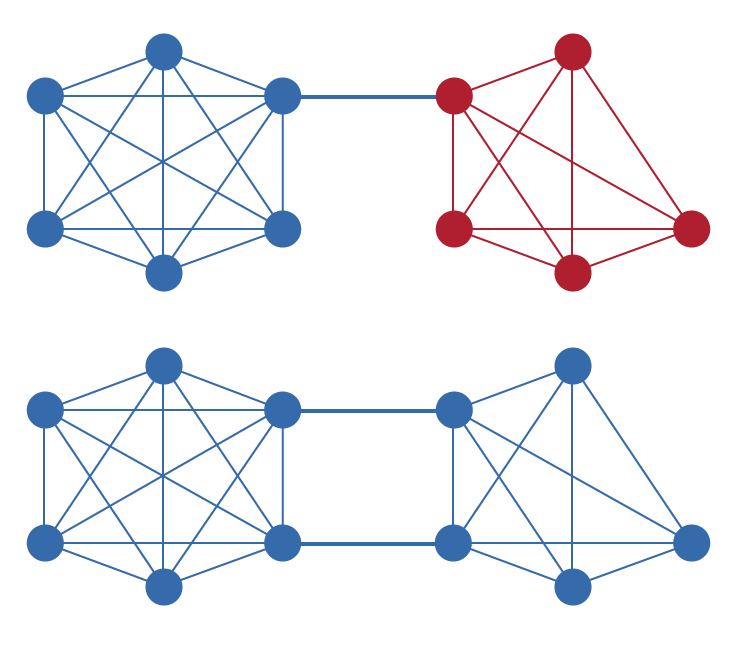
UNL đóng vai trò cơ chế chống tấn công Sybil mà không cần proof-of-work. Trong hệ bỏ phiếu ngây thơ, kẻ tấn công có thể tạo nhiều danh tính giả để giành ảnh hưởng không cân xứng. Bằng cách buộc mỗi nút phải chỉ rõ nó tin nút nào, RPCA bảo đảm việc tạo thêm danh tính không mang lại lợi thế trừ khi các danh tính đó thuyết phục được các nút hiện có thêm chúng vào UNL. Nhờ đó, bài toán kháng Sybil được chuyển từ chi phí tính toán sang quan hệ uy tín và tin cậy.
Để mạng hoạt động đúng, UNL phải được chọn sao cho có độ chồng lấn đủ lớn như đã nêu trong phân tích hình thức. Trong thực tế, điều này có nghĩa là dù mỗi nhà vận hành nút có quyền tự chủ khi chọn UNL, họ vẫn cần bảo đảm danh sách của mình bao gồm các validator cũng được các phần khác của mạng tin cậy. Ripple cung cấp một UNL mặc định gồm các validator do nhiều thực thể vận hành, nhưng nhà vận hành có thể điều chỉnh danh sách này theo đánh giá tin cậy riêng.
Cơ chế UNL cũng tạo ra con đường tự nhiên hướng đến phi tập trung dần theo thời gian. Ở giai đoạn đầu của mạng, tập validator tập trung hơn có thể phù hợp để bảo đảm ổn định và độ tin cậy. Khi mạng trưởng thành và nhiều nhà vận hành đa dạng chứng minh được uy tín, UNL có thể tiến hóa để bao gồm tập validator rộng hơn, tăng khả năng chống chịu và mức độ phi tập trung mà không làm suy giảm các thuộc tính bảo mật.
Unique Node Lists
唯一节点列表(UNL)是RPCA区别于其他共识算法的基本组件。Ripple网络中的每个节点维护一个UNL,包含它信任不会串通欺骗网络的其他节点。关键的是,这种信任是局部的而非全局的:不同的节点可以有不同的UNL,不需要全局统一的验证者集合。这种设计允许网络在保持去中心化的同时有机地扩展。
UNL作为一种无需工作量证明的Sybil攻击防御机制。在简单的投票系统中,攻击者可以创建许多假名节点以获得不成比例的影响力。通过要求每个节点明确选择它信任的其他节点,RPCA确保创建额外的身份不会带来任何优势,除非这些身份能够说服现有节点将其添加到UNL中。这将Sybil抵抗的问题从计算支出转移到了声誉和信任关系上。
为使网络正确运行,UNL必须按照形式化分析中所述选择具有足够重叠的列表。在实践中,这意味着虽然每个节点运营者在选择UNL方面拥有自主权,但必须确保其列表中包含网络其他部分也信任的验证者。Ripple提供了一个由多元化实体运营的验证者组成的默认UNL,但节点运营者可以根据自己的信任评估自由修改此列表。
UNL机制还提供了一条通向渐进式去中心化的自然路径。在网络的早期阶段,更集中的验证者集合可能更适合确保稳定性和可靠性。随着网络的成熟和更多多元化运营者证明其可信度,UNL可以演变为包含更广泛的验证者集合,在不损害安全属性的情况下增强网络的韧性和去中心化程度。
Simulation Code
Để kiểm chứng phân tích lý thuyết của RPCA và đánh giá hiệu năng dưới nhiều điều kiện, các mô phỏng quy mô lớn đã được thực hiện bằng phần mềm mô phỏng tùy biến. Khung mô phỏng mô hình hóa một mạng các nút, mỗi nút duy trì UNL riêng và tham gia giao thức đồng thuận. Mã nguồn triển khai đầy đủ thuật toán RPCA, bao gồm đề xuất giao dịch, các vòng bỏ phiếu với ngưỡng tăng dần và xác thực sổ cái.
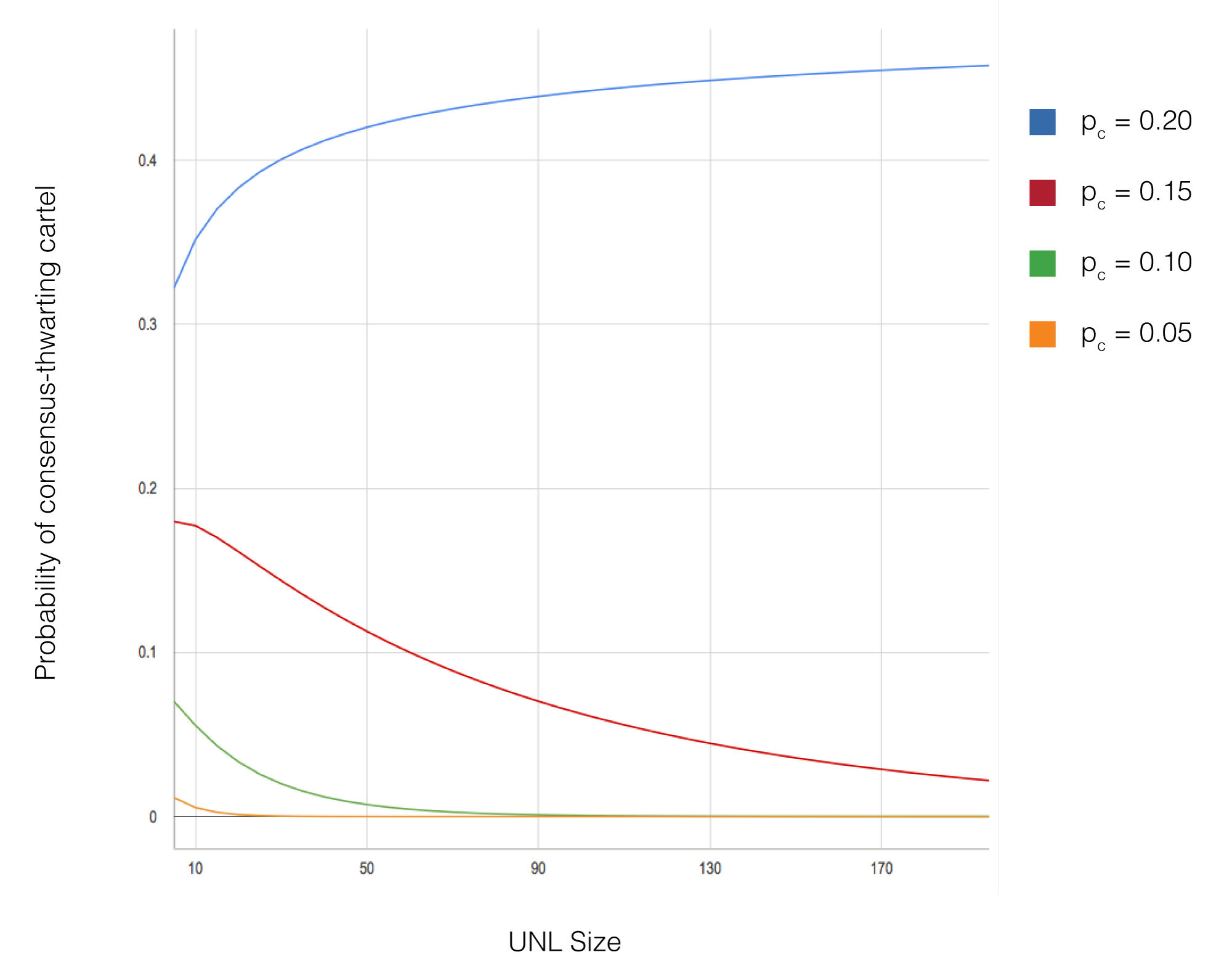
Các tham số chính được thay đổi trong mô phỏng gồm kích thước mạng (từ 10 đến 1.000 nút), tỷ lệ nút Byzantine (từ 0% đến 20%), kích thước UNL (thường từ 5 đến 50 nút), và cấu hình topology mạng. Với mỗi cấu hình tham số, nhiều lần chạy mô phỏng được thực hiện với các random seed khác nhau để bảo đảm độ tin cậy thống kê của kết quả. Các mô phỏng theo dõi các chỉ số như độ trễ đồng thuận, xác suất phân nhánh, và thông lượng giao dịch.
Kết quả mô phỏng xác nhận các dự đoán lý thuyết về hội tụ và an toàn. Trong mọi cấu hình mà điều kiện chồng lấn UNL được thỏa và tỷ lệ Byzantine trong mỗi UNL dưới 20%, mạng đạt đồng thuận thành công mà không xảy ra phân nhánh. Độ trễ đồng thuận luôn thấp (thường hoàn tất trong 3-5 giây mô phỏng) bất kể kích thước mạng, cho thấy tính mở rộng của thuật toán. Ngay cả khi 15% nút Byzantine chủ động phá hoại đồng thuận, mạng vẫn giữ được tính đúng đắn miễn là điều kiện chồng lấn UNL được đáp ứng.
Các mô phỏng bổ sung cũng khảo sát các trường hợp biên và kịch bản lỗi, gồm phân vùng mạng, thay đổi đột ngột thành phần UNL, và tấn công phối hợp của các nút Byzantine. Các mô phỏng này cung cấp thêm hiểu biết về độ vững chắc của giao thức và định hình các thực hành tốt nhất được khuyến nghị cho lựa chọn UNL và vận hành mạng. Toàn bộ mã mô phỏng đã được công bố để cho phép kiểm chứng độc lập và nghiên cứu tiếp theo.
Simulation Code
为验证RPCA的理论分析并评估其在各种条件下的性能,使用定制的仿真软件进行了大量模拟。仿真框架对节点网络进行建模,每个节点维护自己的UNL并参与共识协议。代码实现了完整的RPCA算法,包括交易提案、阈值递增的投票轮次和账本验证。
模拟中变化的关键参数包括网络规模(从10到1,000个节点)、Byzantine节点的百分比(从0%到20%)、UNL大小(通常在5到50个节点之间)和网络拓扑配置。对于每种参数配置,使用不同的随机种子进行了多次模拟运行,以确保结果的统计有效性。模拟跟踪了包括共识延迟、分叉概率和交易吞吐量在内的指标。
模拟结果证实了关于收敛和安全性的理论预测。在UNL重叠条件满足且Byzantine节点占每个UNL不到20%的所有配置中,网络成功达成共识且未出现分叉。共识延迟始终保持较低水平(通常在3-5秒的模拟时间内完成),与网络规模无关,证明了算法的可扩展性。即使有15%的Byzantine节点积极尝试破坏共识,只要满足UNL重叠要求,网络仍保持正确性。
额外的模拟探索了边缘情况和故障场景,包括网络分区、UNL组成的突然变化和Byzantine节点的协调攻击。这些模拟提供了关于协议鲁棒性的洞察,并为UNL选择和网络运营的推荐最佳实践提供了参考。完整的模拟代码已公开发布,以便进行独立验证和进一步研究。
Discussion
So với đồng thuận proof-of-work của Bitcoin, RPCA mang lại nhiều lợi thế đáng kể cho các ứng dụng hệ thống thanh toán. Nổi bật nhất là độ trễ đồng thuận giảm từ 40-60 phút (thời gian thường được khuyến nghị cho giao dịch Bitcoin giá trị cao) xuống khoảng 5 giây. Cải thiện này khiến RPCA phù hợp cho điểm bán hàng và các ứng dụng đòi hỏi quyết toán gần như tức thời. Ngoài ra, RPCA yêu cầu tài nguyên tính toán tối thiểu so với proof-of-work, loại bỏ mức tiêu thụ năng lượng khổng lồ gắn với hoạt động đào Bitcoin.
Tuy nhiên, các lợi thế này đi kèm giả định tin cậy khác. Trong khi bảo mật của Bitcoin chỉ dựa trên giả định không có kẻ tấn công nào kiểm soát quá 50% năng lực tính toán toàn mạng, RPCA yêu cầu các nút chọn UNL có độ chồng lấn đủ lớn và số nút Byzantine không vượt ngưỡng trong các UNL đó. Điều này chuyển một phần trách nhiệm sang nhà vận hành nút trong việc đưa ra quyết định tin cậy thận trọng. Trong thực tế, đánh đổi này chấp nhận được trong nhiều bối cảnh thanh toán nơi các tổ chức tham gia vốn đã có quan hệ tin cậy.
Topology mạng và chiến lược chọn UNL ảnh hưởng mạnh đến đặc tính của hệ đồng thuận. Topology tập trung cao, nơi mọi nút cùng dùng chung validator trong UNL, tối đa hóa an toàn nhưng có thể làm giảm tính sống nếu các validator đó không khả dụng. Ngược lại, topology phi tập trung cao với độ chồng lấn UNL thấp có thể cải thiện tính sống nhưng làm tăng rủi ro thất bại đồng thuận nếu chồng lấn trở nên quá thưa. Việc tìm điểm cân bằng tối ưu đòi hỏi cân nhắc kỹ kịch bản triển khai cụ thể và mức chấp nhận rủi ro.
Các hướng nghiên cứu tương lai có thể gồm thuật toán chọn UNL thích nghi tự động duy trì điều kiện chồng lấn trong khi tối đa hóa phi tập trung, cơ chế để nút điều chỉnh UNL động theo hành vi validator quan sát được, và mở rộng thuật toán đồng thuận để chịu được tỷ lệ nút Byzantine cao hơn nữa. Những cải tiến này có thể tiếp tục nâng cao độ vững chắc và phạm vi ứng dụng của RPCA cho các hệ thống thanh toán phân tán quy mô lớn.
Discussion
与比特币的工作量证明共识相比,RPCA为支付系统应用提供了几个显著优势。最值得注意的是,共识延迟从40-60分钟(高价值比特币交易通常建议的时间)减少到约5秒。这一改进使RPCA适用于需要近乎即时结算的销售点和其他应用。此外,RPCA与工作量证明相比所需的计算资源极少,消除了与比特币挖矿相关的大量能源消耗。
然而,这些优势伴随着不同的信任假设。比特币的安全性仅依赖于没有攻击者控制网络计算能力50%以上的假设,而RPCA要求节点选择具有足够重叠的UNL,并且Byzantine节点不超过这些UNL内的阈值。这将部分做出审慎信任决策的责任转移给了节点运营者。在实践中,对于参与机构拥有现有信任关系的许多支付系统用例,这种权衡是可以接受的。
网络拓扑和UNL选择策略显著影响共识系统的属性。所有节点在UNL中包含相同验证者的高度集中化拓扑最大化了安全性,但如果这些验证者不可用,可能会降低活性。相反,UNL重叠最小的高度去中心化拓扑可能改善活性,但如果重叠变得过于稀疏,则存在共识失败的风险。找到最佳平衡需要仔细考虑特定的部署场景和风险承受能力。
未来的研究可以探索在最大化去中心化的同时自动维护重叠要求的自适应UNL选择算法、节点根据观察到的验证者行为动态调整UNL的机制,以及可以容忍更高比例Byzantine节点的共识算法扩展。这些增强可以进一步提高RPCA在大规模分布式支付系统中的鲁棒性和适用性。
Conclusion
Thuật toán Đồng thuận Giao thức Ripple là một bước tiến quan trọng của đồng thuận phân tán cho hệ thống thanh toán. Bằng cách sử dụng các mạng con được tin cậy tập thể thay vì yêu cầu đồng thuận toàn cục giữa mọi nút, RPCA đạt đồng thuận trong vài giây mà vẫn giữ bảo đảm mạnh trước lỗi Byzantine. Phân tích hình thức cho thấy rằng khi UNL được chọn với độ chồng lấn đủ lớn và tỷ lệ nút Byzantine nằm dưới ngưỡng, mạng sẽ đạt đồng thuận đúng mà không phân nhánh.
Ý nghĩa thực tiễn của công trình này vượt ra ngoài mạng thanh toán Ripple. RPCA cho thấy đánh đổi truyền thống giữa độ trễ đồng thuận và bảo đảm bảo mật có thể được vượt qua bằng thiết kế giao thức cẩn thận và việc khai thác quan hệ tin cậy cục bộ. Cách tiếp cận này có thể áp dụng cho các hệ phân tán khác nơi độ trễ thấp là yếu tố then chốt và các bên tham gia có quan hệ tin cậy sẵn có, như thanh toán liên ngân hàng, theo dõi chuỗi cung ứng, và các hạ tầng tài chính khác.
Việc triển khai RPCA trong môi trường sản xuất đã xác nhận đặc tính hiệu năng và độ vững chắc của thuật toán. Mạng Ripple xử lý hàng nghìn giao dịch mỗi giây với độ trễ đồng thuận ổn định 3-5 giây, chứng minh rằng các thuộc tính lý thuyết có thể chuyển hóa hiệu quả thành vận hành thực tế. Khi mạng tiếp tục phát triển và bổ sung thêm validator từ các nhà vận hành đa dạng, nó trở thành ví dụ thực tiễn về cách một hệ đồng thuận phi tập trung có thể duy trì đồng thời bảo mật và hiệu năng ở quy mô lớn.
Conclusion
Ripple协议共识算法代表了支付系统分布式共识的重要进步。通过利用集体信任的子网络而非要求所有节点之间的全局一致,RPCA在维持对Byzantine故障的强大保障的同时,在几秒内达成共识。形式化分析表明,只要UNL以足够的重叠选择且Byzantine节点保持在阈值以下,网络将达成正确的共识而不会出现分叉。
本研究的实际意义超越了Ripple支付网络。RPCA表明,共识延迟与安全保障之间的传统权衡可以通过精心的协议设计和局部信任关系的使用来克服。这种方法可能适用于其他低延迟至关重要且参与者拥有现有信任关系的分布式系统,如银行间结算系统、供应链跟踪以及其他金融基础设施应用。
RPCA在生产系统中的部署验证了算法的性能特征和鲁棒性。Ripple网络以一致的3-5秒共识延迟处理每秒数千笔交易,证明了理论属性有效地转化为实际运营。随着网络继续演进并纳入来自多元化运营者的额外验证者,它提供了一个去中心化共识系统如何在规模上同时维持安全性和性能的实际案例。
References
Lamport, L., Shostak, R., và Pease, M. (1982). "The Byzantine Generals Problem." ACM Transactions on Programming Languages and Systems, 4(3):382-401. Công trình nền tảng này đã hình thức hóa bài toán đạt đồng thuận trong hệ phân tán có thành phần lỗi và đặt nền móng lý thuyết cho các hệ chịu lỗi Byzantine.
Castro, M., và Liskov, B. (1999). "Practical Byzantine Fault Tolerance." Proceedings of the Third Symposium on Operating Systems Design and Implementation (OSDI). Công trình này giới thiệu PBFT, cho thấy chịu lỗi Byzantine có thể đạt được với hiệu năng thực tiễn, dù độ phức tạp truyền thông O(n^2) giới hạn khả năng mở rộng.
Nakamoto, S. (2008). "Bitcoin: A Peer-to-Peer Electronic Cash System." Whitepaper này giới thiệu đồng thuận proof-of-work như lời giải cho bài toán chi tiêu kép trong tiền tệ số, cho phép đồng thuận phi tập trung không cần bên tin cậy nhưng đánh đổi bằng độ trễ cao và tiêu thụ năng lượng lớn.
Lamport, L. (1998). "The Part-Time Parliament." ACM Transactions on Computer Systems, 16(2):133-169. Bài báo này trình bày thuật toán Paxos, đạt đồng thuận trong hệ bất đồng bộ dưới lỗi sập và có ảnh hưởng lớn đến thiết kế các giao thức đồng thuận về sau.
Fischer, M. J., Lynch, N. A., và Paterson, M. S. (1985). "Impossibility of Distributed Consensus with One Faulty Process." Journal of the ACM, 32(2):374-382. Kết quả bất khả thi FLP thiết lập giới hạn cơ bản về những gì thuật toán đồng thuận có thể đạt trong hệ bất đồng bộ, qua đó định hình không gian thiết kế cho các giao thức đồng thuận thực tế.
References
Lamport, L., Shostak, R., and Pease, M. (1982). "The Byzantine Generals Problem." ACM Transactions on Programming Languages and Systems, 4(3):382-401. 这篇开创性论文形式化了在具有故障组件的分布式系统中达成共识的问题,并建立了Byzantine fault-tolerant系统的理论基础。
Castro, M., and Liskov, B. (1999). "Practical Byzantine Fault Tolerance." Proceedings of the Third Symposium on Operating Systems Design and Implementation (OSDI). 该研究引入了PBFT,表明Byzantine fault tolerance可以以实用的性能实现,尽管O(n^2)的通信复杂度限制了可扩展性。
Nakamoto, S. (2008). "Bitcoin: A Peer-to-Peer Electronic Cash System." 该白皮书引入了工作量证明共识作为数字货币中双重支付问题的解决方案,以高延迟和能源消耗为代价实现了无需可信方的去中心化共识。
Lamport, L. (1998). "The Part-Time Parliament." ACM Transactions on Computer Systems, 16(2):133-169. 该论文提出了Paxos算法,在崩溃故障下的异步系统中达成共识,影响了后续共识协议的设计。
Fischer, M. J., Lynch, N. A., and Paterson, M. S. (1985). "Impossibility of Distributed Consensus with One Faulty Process." Journal of the ACM, 32(2):374-382. FLP不可能性结果确立了异步系统中共识算法所能达到的基本限制,塑造了实用共识协议的设计空间。




